AV1 and more … how does Jitsi Meet pick video codecs?
Say hello to AV1, the new default video codec in Jitsi Meet
![]()
The AV1 codec represents the cutting edge of video compression technology. Developed by the Alliance for Open Media (AOMedia), a consortium including tech giants like Google, Microsoft, Netflix, and Mozilla, AV1 is a loyalty-free video codec that was designed to meet the ever-growing demand for high-quality video streaming while minimizing bandwidth usage.
It offers up to 30-50% better compression compared to its predecessors like VP9, VP8 and H.264, enabling sharper visuals at lower bitrates. This makes it an ideal choice for bandwidth-constrained environments, such as mobile networks or rural areas with limited internet speeds. Despite its impressive capabilities, the adoption of AV1 has been slower than anticipated due to several factors. AV1 has higher computational demands as its advanced compression algorithms require significantly more processing power for encoding and decoding. Hardware acceleration for AV1 is still emerging and therefore use of AV1 can result in higher CPU/energy consumption and suboptimal performance on low end devices and those without hardware support.
The path to adding AV1 support in Jitsi was not straightforward. Before we could enable AV1, it was essential to integrate support for the various modes and complexities that the codec offers, both in the Jitsi Meet client and the Jitsi Video Bridge (JVB). Jitsi had to extend JVB’s capabilities to handle AV1 streams, including managing simulcast and SVC modes seamlessly for multi-user conferences. This groundwork laid the foundation for AV1’s eventual inclusion as the preferred codec in Jitsi deployments.
AV1’s RTP encapsulation is unusual, if not weird, compared to RTP payloads for other video codecs – all the information an RTP Selective Forwarding Unit (SFU) like the JVB needs is carried in a “Dependency Descriptor” RTP header extension, rather than in the RTP payload proper. This means that the JVB doesn’t technically need to support the AV1 codec at all – it only needs to support the dependency descriptor header extension.
Decoding AV1’s Dependency Descriptor
This format is unusual in that it was developed not in the IETF, where RTP payload formats are normally defined, but rather by AOMedia itself. The main consequence of this is that the header is encoded very much like a video codec: it’s very parsimonious of bit usage, at the cost of being both annoyingly complicated to parse, and being stateful – information needed to parse the header is sent only at intervals. For more information about this complexity, see Lorenzo’s post from several years ago – https://www.meetecho.com/blog/av1-svc/.
Handling the complex parsing is relatively straightforward once some utility classes are written. However, handling the statefulness is harder, especially given that an SFU always needs to be prepared for packet loss and reordering, so packets that use some state may arrive before the packet that provides it. Thus this work needs to keep track of the state that’s reported in those packets that carry it, and pass it forward to the parser to parse subsequent headers, while handling the possibility that a state update may have been missed.
Because the AV1 DD is a header extension, it can be applied to codecs other than AV1 itself. Notably, this allows us to indicate temporal scalability of an H.264 stream, which is useful because H.264 (without its little-implemented SVC extensions) has no way to indicate temporal scalability of its packets. As a result, the work to support the AV1 DD also allows Jitsi to enable scalable H.264 streams for JVB-mediated conferences as well! (Though there are currently some bugs in Chrome that make this less efficient than it could be – see here and here.) In fact the header can be applied to any video codec, though we still prefer to handle VP8 and VP9 using their in-payload information when that information is available.
Another notable feature of the AV1 dependency descriptor is its concept of “decode targets”, which are a specific layer that a decoder can decode, and thus that an SFU can forward. These usually correspond to a specific spatial and temporal layer, but technically they do not have to. The idea is that a decoder can choose among the various decode targets present in the stream. In most cases it would want to choose the highest-quality one available, but in some circumstances (for instance if it was CPU-constrained, or displaying a source in a small window) it could choose a lower-quality target instead.
This has the consequence that a stream needs to be explicit about what decode targets are actually present. An SFU, by design, forwards only some of the layers in a stream; this is what it means to “selectively forward”. As a result, the ultimate decoder needs to know what layers it can actually expect to receive, vs. which ones it won’t receive, or it can end up waiting forever while it never gets the frames it thinks it should render. To handle this case, the AV1 dependency descriptor contains a decode target bitmask in the AV1 header extension to indicate which layers are still present in the stream. This bitmask then needs to be updated every time the SFU changes its layer forwarding decision, so the decoder doesn’t try to wait to decode a decode target that won’t be arriving any more, or, conversely, so it can know to start decoding a new layer that’s newly started arriving. Fortunately, the logic to do this work is not too complicated, and is similar in complexity to the logic needed to modify the in-payload information for forward VP8 or VP9 streams.
Scalable Video Coding (SVC) Extension for WebRTC
With the release of Chromium M111, significant advancements were made in WebRTC, particularly with the introduction of Scalable Video Coding (SVC) support. This update enabled WebRTC applications to configure encoding parameters for SVC by extending the RTCRtpEncodingParameters dictionary. Around the same time, Chrome also introduced AV1 and VP9 simulcast support. Before Chromium M111, the K-SVC mode (Keyframe-scalable video coding) was the only supported mode for SVC. This update allowed Jitsi Meet to experiment with various scalability modes for AV1 and VP9.
In a Jitsi conference, the client and JVB work in tandem to ensure efficient video streaming. This involves an ongoing exchange of sender and receiver video constraints.
- Receiver Constraints: Each participant sends constraints (e.g., desired resolution and priority) to the JVB for the video streams they want to receive. These constraints are influenced by the participant’s current layout (e.g., larger tiles for active speakers).
- Sender Constraints: JVB aggregates these constraints and communicates the required video resolutions to the senders. This ensures a participant only sends higher-resolution streams (e.g., 720p) if at least one other participant views them in a sufficiently large tile.
This dynamic coordination minimizes bandwidth usage and optimizes network resources while maintaining the quality of the user experience. Once the client receives sender constraints, it configures its outbound video streams using RTCRtpEncodingParameters. These parameters are tailored based on:
- Resolution: The effective resolution determined by JVB constraints.
- Video Type: Camera or desktop sharing (further based on content type).
- Codec Operating Mode: Whether the stream uses full SVC, simulcast, or unicast.
For AV1 and VP9, three operating modes were tested:
- Full SVC Mode: Uses L3T3 (3 spatial layers, 3 temporal layers) and L2T3 (2 spatial layers, 3 temporal layers) scalability modes.
- K-SVC Mode: Employs L3T3_KEY and L2T3_KEY scalability modes, focusing on keyframe-based scalability.
- Simulcast Mode: Configures each simulcast layer with L1T3 (single spatial layer, 3 temporal layers).
SVC allows a single video stream to be encoded in layers, each layer adding more detail or resolution to the base stream while simulcast involves sending multiple independent video streams of the same content, each at a different resolution and bitrate.
| Aspect | Simulcast | SVC |
Encoding |
Multiple streams encoded separately. |
One stream encoded with multiple layers. |
Bandwidth Usage (Sender) |
Higher (multiple streams). |
Lower (single stream). |
CPU Usage (Sender) |
High (due to multiple encodings). |
Lower (single encoding with layers). |
CPU Usage (Receiver) |
Lower (no need to decode layers). |
Higher (decoding layered streams). |
| Adaptability | Coarser (switching between streams). |
Finer (dynamic layer adjustment). |
Compatibility |
Broadly supported in WebRTC platforms. |
Limited support, requires advanced codecs. |
After extensive performance testing and careful evaluation of product requirements, Jitsi selected full SVC mode as the default configuration for both AV1 and VP9. This choice ensures optimal scalability and video quality across Jitsi’s deployments. However, this behavior is not rigid; it is configurable and can be easily overridden through config.js settings, providing flexibility to adapt to specific use cases or deployment needs.
Choosing “The One”
To determine the optimal video codec for use in the Jitsi Meet client, Jitsi conducted comprehensive testing under realistic conditions to ensure that codec selection would meet product needs for quality, performance, and scalability. Below is an overview of the methodologies and considerations involved:
Testing Scenarios
- Bandwidth Variations – Simulations spanned low, medium, and high bandwidth environments. The goal was to assess how each codec managed network fluctuations while maintaining quality.
- Latency and Packet Loss – Varying levels of latency and packet loss were introduced to evaluate codec resilience. Stress tests were performed to observe behavior under severe conditions, such as 30% packet loss or latency spikes of 300ms.
- Device Diversity – Tests were conducted on a range of hardware, including Windows and macOS devices and multiple operating systems, to measure CPU load and adaptability. Both high-end and low-end systems were evaluated to cover a wide user base.
Metrics Captured
- CPU Usage – Encoding and decoding performance were assessed, focusing on average encode times (in milliseconds). Data was derived from totalEncodeTime stats in outbound RTP streams, with averages computed across test runs.
- Bandwidth Efficiency – The minimum bitrate required to deliver acceptable video quality was recorded. Metrics were analyzed for each codec to identify which offered optimal quality for a given bitrate.
- Scalability Performance – Tested the ability of each codec to handle spatial and temporal scalability. Metrics such as switch latency (time to adjust to new sender constraints) were captured to evaluate adaptability during resolution and frame rate changes.
- User Experience Metrics – Frame drops and jitter were monitored to quantify playback quality. Recovery time after network disruptions or resolution changes was measured, ensuring codecs could handle dynamic conditions effectively.
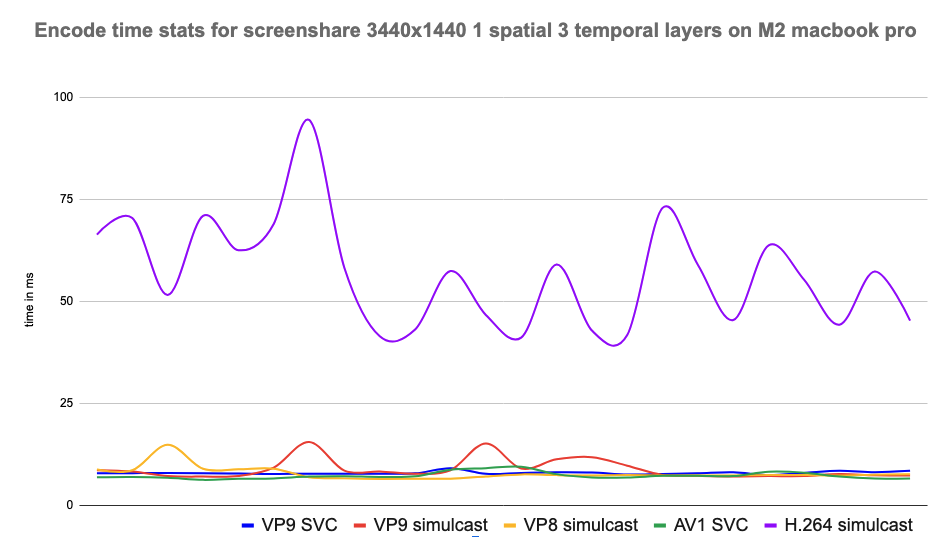
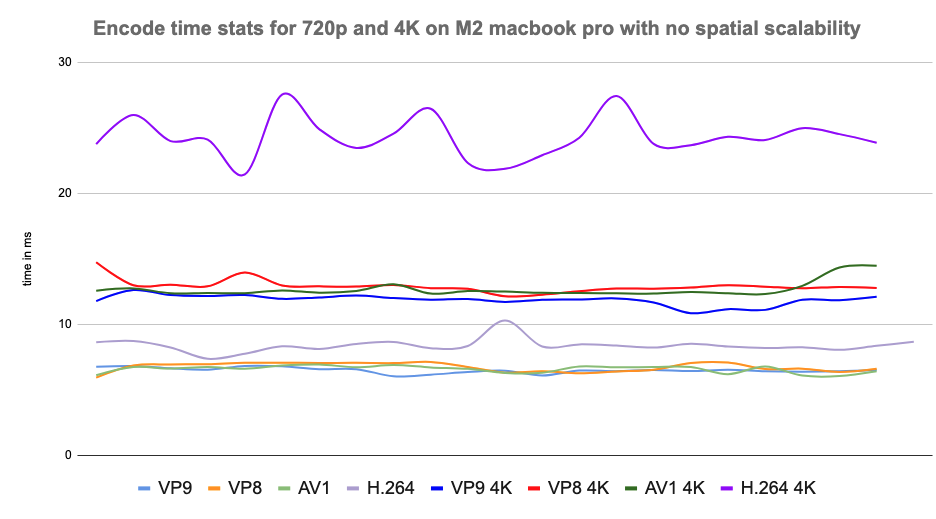
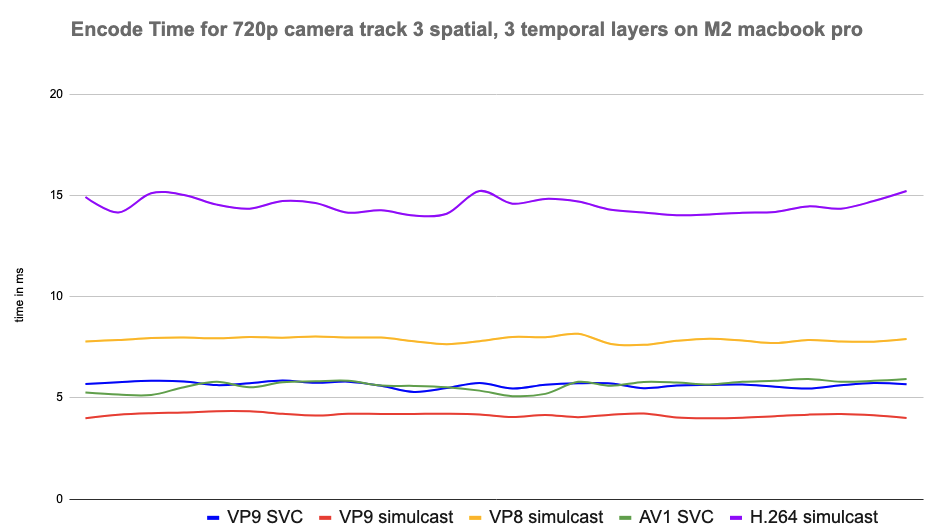
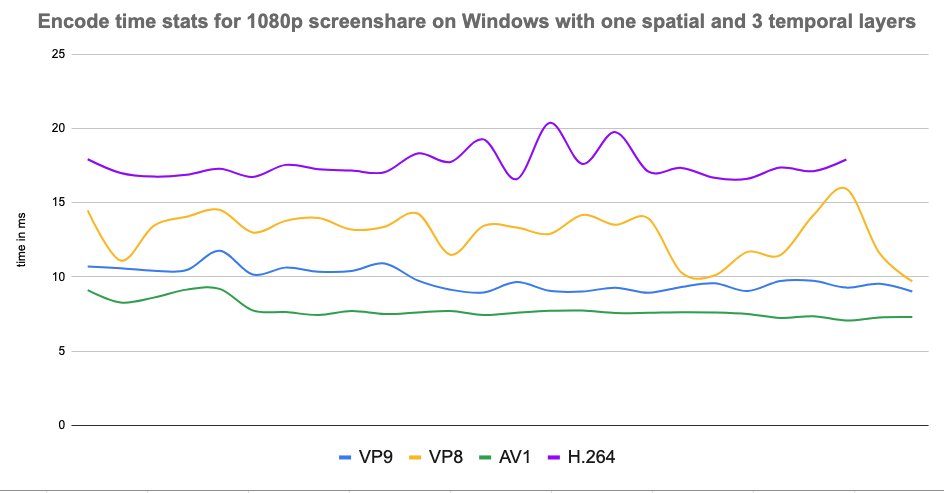
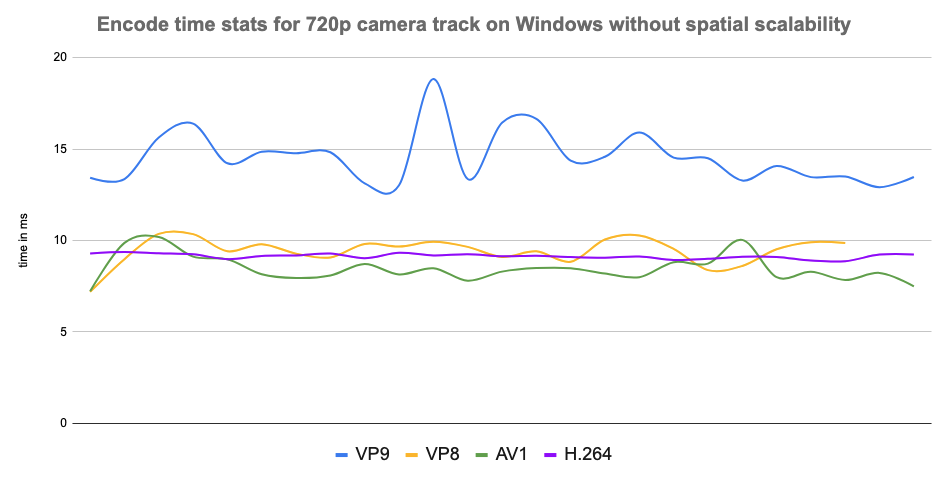
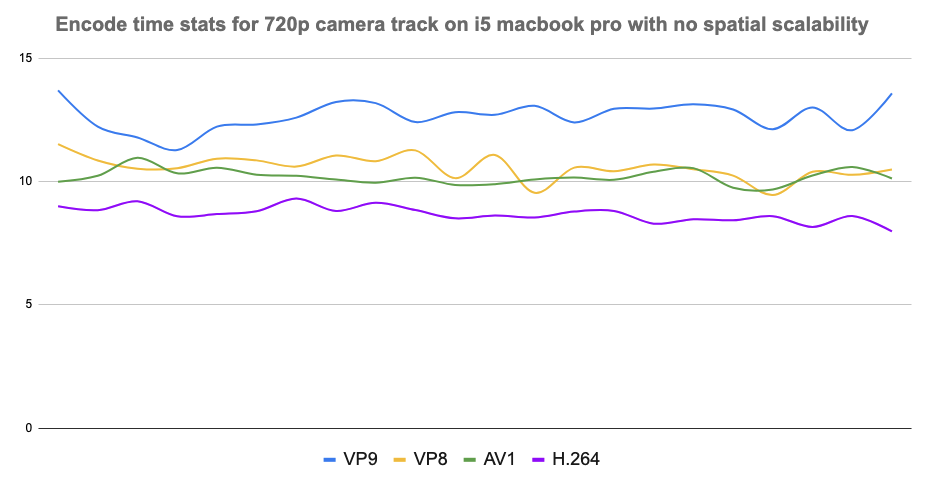
Results and observations
- AV1: Delivered superior video quality at low bitrates but required higher CPU power (but surprisingly on par with VP9 in some cases), making it ideal for high-quality sessions on modern devices. It turned out that it was the best codec for screen sharing on all platforms because of how it uses screen content coding to achieve low bitrates without compromising on video quality and using low CPU, all at the same time.
- VP9: Balanced bandwidth efficiency and CPU usage, proving effective for scalable video streams in multi-party calls.
- VP8: Demonstrated resilience under suboptimal conditions but lagged in scalability and modern features compared to newer codecs.
- H.264: Showed minimal CPU usage only where hardware acceleration was supported. The CPU usage was much higher when it was done in software, especially for higher resolutions like 4K and screenshare. It also struggled with bandwidth efficiency and adaptability in low-bandwidth scenarios.
By rigorously analyzing these metrics, Jitsi optimized its codec selection strategy. While Full SVC modes remained the default for high-performance scenarios, fallback options like VP9 and VP8 were configured for legacy or resource-constrained devices. This comprehensive approach ensures that the Jitsi Meet client provides the best possible video experience across a wide range of devices and network conditions.
Addressing CPU overuse with Adaptive Mode in Jitsi Meet
With the integration of AV1 into Jitsi Meet, users benefit from superior compression and high-quality video at lower bitrates. However, these advantages come at the cost of increased computational demands, especially on low-end devices. To address this, Jitsi introduced a three-fold adaptive quality control mechanism, ensuring a seamless experience even under CPU constraints.
How Adaptive Mode Works
- Decreasing the Encoding Load
- Dynamic Codec Switching:
In adaptive mode, the Jitsi Meet client monitors the WebRTC stats for outbound RTP streams. If the stats indicate a CPU limitation, the client iteratively switches to a lower-complexity codec. This process continues until the lowest complexity codec is reached, based on predefined performance benchmarks for each video type (e.g., camera feed, screen share) thereby reducing the computational demand of video encoding without significantly compromising video quality.
- Dynamic Codec Switching:
- Decreasing the Decoding Load
- Requesting Fewer Videos: If reducing encoding complexity isn’t sufficient, the client requests fewer video streams from the server. This limits the number of video decoders active at a given time, cutting down CPU usage.
- Lowering Received Video Resolution: For videos already being received, the client requests lower resolutions, further reducing decoding requirements. This helps balance computational load while maintaining an acceptable user experience.
This adaptive approach enables Jitsi Meet to leverage the advanced capabilities of AV1 while ensuring that users with diverse hardware configurations can participate in meetings without disruptions caused by excessive CPU usage.
However, when the CPU spike originates from an external process rather than the Jitsi Meet client, the adaptive mode ensures that quality degradation is minimal. To enhance the user experience, Jitsi Meet also incorporates a recovery mechanism that restores the video configuration once the external constraints are resolved.
Mechanism for Recovery
- Continuous Monitoring
- The client monitors the CPU limitation statistics reported by the browser through WebRTC metrics. If the browser no longer reports CPU constraints, the client initiates a recovery sequence.
- Incremental Recovery Process
- The recovery mechanism keeps increasing the number of remote video streams the client requests from the JVB until it reaches the limit set for the conference.
- This process is incremental to prevent sudden spikes in CPU usage that could destabilize the client.
- Dynamic Adjustment
- If CPU constraints reappear during the recovery process, the client halts further recovery steps. This ensures the system does not enter a state where CPU usage exceeds the device’s capabilities.
This gradual approach minimizes the risk of overloading the system during recovery. It also adapts to fluctuating CPU availability, maintaining a balance between performance and quality. The client handles this entire process dynamically without any user interaction, providing a seamless experience.
Browser / device support
Firefox and Safari do not advertise support for the AV1 codec yet. As a result, when users on these browsers join a call, all other participants automatically switch to the next codec in the preferred list, ensuring compatibility across all endpoints.
Additionally, while Chromium-based mobile endpoints are capable of both encoding and decoding AV1, Jitsi has opted to use AV1 only for decoding. For encoding, a lower-complexity codec is used, as encoding typically imposes a higher CPU load compared to decoding. This decision balances performance and device resource constraints, especially on mobile devices.
Eager to start using AV1 in Jitsi?
We have great news for you then!! AV1 support was introduced to Jitsi in June 2024 and has been available in our stable packages ever since. Initially, AV1 had to be manually configured as the preferred codec through config.js settings, allowing users to opt in.
Building on this, AV1 was soon made the preferred codec on meet.jit.si, marking a significant step in leveraging its advanced compression capabilities. Starting with release stable-9909, AV1 became the default preferred codec in our Docker deployments, ensuring out-of-the-box support for users opting for containerized setups.
After thorough experimentation and analysis of real-world performance data, we’re excited to share that AV1 will very soon become the default preferred codec in all deployments, bringing its exceptional bandwidth efficiency and video quality to a broader audience. Stay tuned!
Happy holidays!
 Your personal meetings team.
Your personal meetings team.
P.S – With contributions from Jonathan Lennox (Jitsi VideoBridge)
The post AV1 and more … how does Jitsi Meet pick video codecs? appeared first on Jitsi.