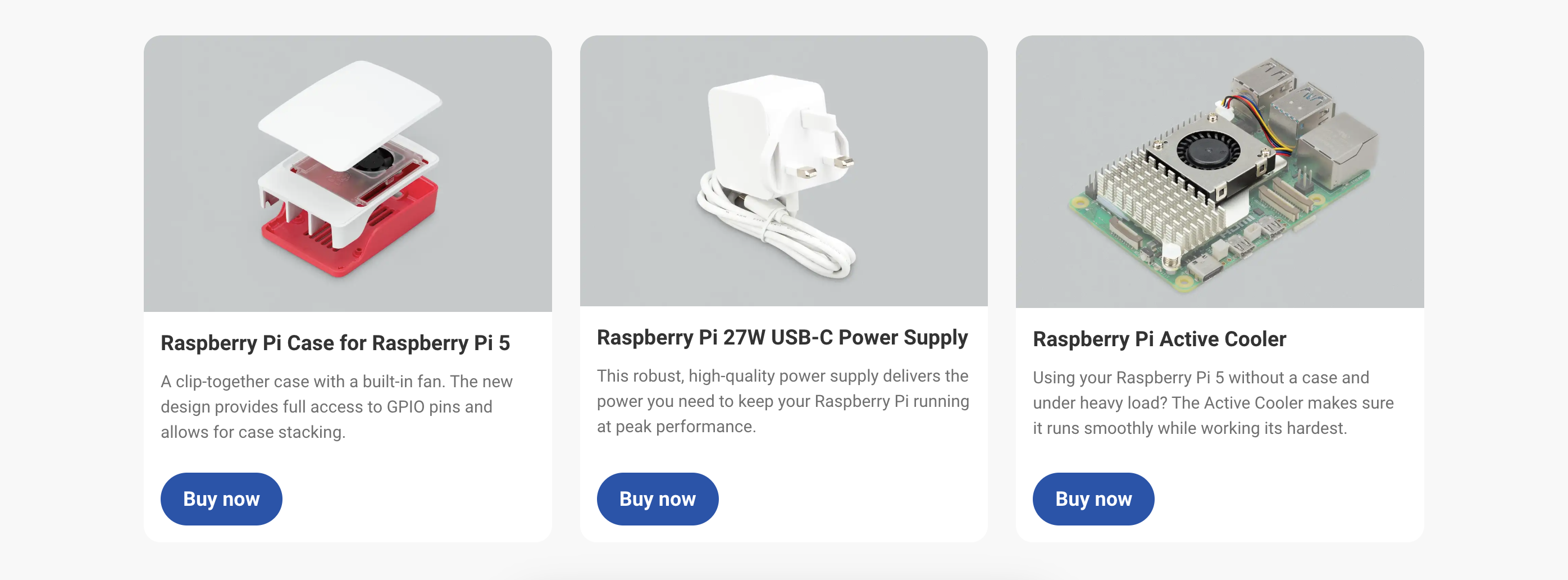
The Powered by Docker is a series of blog posts featuring use cases and success stories from Docker partners and practitioners. This story was contributed by Neal Patel from Siimpl.io. Neal has more than ten years of experience developing software and is a Docker Captain.
Background
As a platform engineer at a mid-size startup, I’m responsible for identifying bottlenecks and developing solutions to streamline engineering operations to keep up with the velocity and scale of the engineering organization. In this post, I outline some of the challenges we faced with one of our clients, how we addressed them, and provide guides on how to tackle these challenges at your company.
One of our clients faced critical engineering challenges, including poor synchronization between development and CI/CD environments, slow incident response due to inadequate rollback mechanisms, and fragmented telemetry tools that delayed issue resolution. Siimpl implemented strategic solutions to enhance development efficiency, improve system reliability, and streamline observability, turning obstacles into opportunities for growth.
Let’s walk through the primary challenges we encountered.
Inefficient development and deployment
Problem: We lacked parity between developer tooling and CI/CD tooling, which made it difficult for engineers to test changes confidently.
Goal: We needed to ensure consistent environments across development, testing, and production.
Unreliable incident response
Problem: If a rollback was necessary, we did not have the proper infrastructure to accomplish this efficiently.
Goal: We wanted to revert to stable versions in case of deployment issues easily.
Lack of comprehensive telemetry
Problem: Our SRE team created tooling to simplify collecting and publishing telemetry, but distribution and upgradability were poor. Also, we found adoption to be extremely low.
Goal: We needed to standardize how we configure telemetry collection, and simplify the configuration of auto-instrumentation libraries so the developer experience is turnkey.
Solution: Efficient development and deployment
CI/CD configuration with self-hosted GitHub runners and Docker Buildx
We had a requirement for multi-architecture support (arm64/amd64), which we initially implemented in CI/CD with Docker Buildx and QEMU. However, we noticed an extreme dip in performance due to the emulated architecture build times.
We were able to reduce build times by almost 90% by ditching QEMU (emulated builds), and targeting arm64 and amd64 self-hosted runners. This gave us the advantage of blazing-fast native architecture builds, but still allowed us to support multi-arch by publishing the manifest after-the-fact.
A managed container orchestration service like Elastic Kubernetes Service (EKS), Azure Kubernetes Service (AKS), or Google Kubernetes Engine (GKE)
Terraform
Helm
Because this project uses industry-standard tooling like Terraform, Kubernetes, and Helm, it can be easily adapted to any CI/CD or cloud solution you need.
Key features
The secret sauce of this solution is provisioning the self-hosted runners in a way that allows our CI/CD to specify which architecture to execute the build on.
The first step is to provision two node pools — an amd64 node pool and an arm64 node pool, which can be found in the aks.tf. In this example, the node_count is fixed at 1 for both node pools but for better scalability/flexibility you can also enable autoscaling for a dynamic pool.
Next, we need to update the self-hosted runners’ values.yaml to have a configurable nodeSelector. This will allow us to deploy one runner scale set to the arm64pool and one to the amd64pool.
Once the Terraform resources are successfully created, the runners should be registered to the organization or repository you specified in the GitHub config URL. We can now update the REGISTRY values for the emulated-build and the native-build.
After creating a pull request with those changes, navigate to the Actions tab to witness the results.
You should see two jobs kick off, one using the emulated build path with QEMU, and the other using the self-hosted runners for native node builds. Depending on cache hits or the Dockerfile being built, the performance improvements can be up to 90%. Even with this substantial improvement, utilizing Docker Build Cloud can improve performance 95%. More importantly, you can reap the benefits during development builds! Take a look at the docker-build-cloud.yml workflow for more details. All you need is a Docker Build Cloud subscription and a cloud driver to take advantage of the improved pipeline.
Leveraging SemVer Tagged Containers for Easy Rollback
Recognizing that deployment issues can arise unexpectedly, we needed a mechanism to quickly and reliably rollback production deployments. Below is an example workflow for properly rolling back a deployment based on the tagging strategy we implemented above.
Rollback Process:
In case of a problematic build, deployment was rolled back to a previous stable version using the tagged images.
AWS CLI commands were used to update ECS services with the desired image tag:
Configuring Sidecar Containers in ECS for Aggregating/Publishing Telemetry Data (OTEL)
As we adopted a OpenTelemetry to standardize observability, we quickly realized that adoption was one of the toughest hurdles. As a team, we decided to bake in as much configuration as possible into the infrastructure (Terraform modules) so that we could easily distribute and maintain observability instrumentation.
Sidecar Container Setup:
Sidecar containers were defined in the ECS task definitions to run OpenTelemetry collectors.
The collectors were configured to aggregate and publish telemetry data from the application containers.
Configuring Multi-Stage Dockerfiles for OpenTelemetry Auto-Instrumentation Libraries (Node.js)
At the application level, configuring the auto-instrumentation posed a challenge since most applications varied in their build process. By leveraging multi-stage Dockerfiles, we were able to help standardize the way we initialized the auto-instrumentation libraries across microservices. We were primarily a nodejs shop, so below is an example Dockerfile for that.
Multi-Stage Dockerfile:
The Dockerfile is divided into stages to separate the build environment from the final runtime environment, ensuring a clean and efficient image.
OpenTelemetry libraries are installed in the build stage and copied to the runtime stage:
# Stage 1: Build stage
FROM node:20 AS build
WORKDIR /app
COPY package.json package-lock.json ./
# package.json defines otel libs (ex. @opentelemetry/node @opentelemetry/tracing)
RUN npm install
COPY . .
RUN npm run build
# Stage 2: Runtime stage
FROM node:20
WORKDIR /app
COPY --from=build /app /app
CMD ["node", "dist/index.js"]
Results
By addressing these challenges we were able to reduce build times by ~90%, which alone dropped our DORA metrics for Lead time for changes and Time to restore by ~50%. With the rollback strategy and telemetry changes, we were able to reduce our Mean time to Detect (MTTD) and Mean time to resolve (MTTR) by ~30%. We believe that it could get to 50-60% with tuning of alerts and the addition of runbooks (automated and manual).
Enhanced Development Efficiency: Consistent environments across development, testing, and production stages sped up the development process, and roughly 90% faster build times with the native architecture solution.
Reliable Rollbacks: Quick and efficient rollbacks minimized downtime and maintained system integrity.
Comprehensive Telemetry: Sidecar containers enabled detailed monitoring of system health and security without impacting application performance, and was baked right into the infrastructure developers were deploying. Auto-instrumentation of the application code was simplified drastically with the adoption of our Dockerfiles.
Siimpl: Transforming Enterprises with Cloud-First Solutions
With Docker at the core, Siimpl.io’s solutions demonstrate how teams can build faster, more reliable, and scalable systems. Whether you’re optimizing CI/CD pipelines, enhancing telemetry, or ensuring secure rollbacks, Docker provides the foundation for success. Try Docker today to unlock new levels of developer productivity and operational efficiency.
We’re excited to announce the General Availability of Docker Bake with Docker Desktop 4.38! This powerful build orchestration tool takes the hassle out of managing complex builds and offers simplicity, flexibility, and performance for teams of all sizes.
What is Docker Bake?
Docker Bake is an orchestration tool that streamlines Docker builds, similar to how Compose simplifies managing runtime environments. With Bake, you can define build stages and deployment environments in a declarative file, making complex builds easier to manage. It also leverages BuildKit’s parallelization and optimization features to speed up build times.
While Dockerfiles are excellent for defining image build steps, teams often need to build multiple images and execute helper tasks like testing, linting, and code generation. Traditionally, this meant juggling numerous docker build commands with their own options and arguments – a tedious and error-prone process.
Bake changes the game by introducing a declarative file format that encapsulates all options and image dependencies, referred to as targets. Additionally, Bake’s ability to parallelize and deduplicate work ensures faster and more efficient builds.
Why should you use Bake?
Challenges with complex Docker Build configuration:
Managing long, complex build commands filled with countless flags and environment variables.
Tedious workflows for building multiple images.
Difficulty declaring builds for specific targets or environments.
Requires a script or 3rd-party tool to make things manageable
Docker Bake tackles these challenges with a better way to manage complex builds with a simple, declarative approach.
Key benefits of Docker Bake
Simplicity: Replace complex chains of Docker build commands and scripts with a single docker buildx bake command while maintaining clear, version-controlled configuration files that are easy to understand and modify.
Flexibility: Express sophisticated build logic through HCL syntax and matrix builds, enabling dynamic configurations that adapt to different environments and requirements while supporting custom functions for advanced use cases.
Consistency: Maintain standardized build configurations across teams and environments through version-controlled files and inheritance patterns, eliminating environment-specific build issues and reducing configuration drift.
Performance: Automatically parallelize independent builds and eliminate redundant operations through context deduplication and intelligent caching, dramatically reducing build times for complex multi-image workflows.
Figure 1: One simple Docker buildx bake command to replace all the flags and environment variables.
Use cases for Docker Bake
1. Monorepo and Image Bakery
Docker Bake can help developers efficiently manage and build multiple related Docker images from a single source repository. Plus, they can leverage shared configurations and automated dependency handling to enforce organizational standards.
Development Efficiency: Teams can maintain consistent build logic across dozens or hundreds of microservices in a single repository, reducing configuration drift and maintenance overhead.
Resource Optimization: Shared base images and contexts are automatically deduplicated, dramatically reducing build times and storage costs.
Standardization: Enforce organizational standards through inherited configurations, ensuring all services follow security, tagging, and testing requirements.
Change Management: A single source of truth for build configurations makes it easier to implement organization-wide changes like base image updates or security patches.
2. Compose users
Docker Bake provides seamless compatibility with existing docker-compose.yml files, allowing direct use of your current configurations. Existing Compose users are able to get started using Bake with minimal effort.
Gradual Adoption: Teams can incrementally adopt advanced build features while still leveraging their existing compose workflows and knowledge.
Development Consistency: Use the same configuration for both local development (via compose) and production builds (via Bake), eliminating “works on my machine” issues.
Enhanced Capabilities: Access powerful features like matrix builds and HCL expressions while maintaining compatibility with familiar compose syntax.
CI/CD Integration: Seamlessly integrate with existing CI/CD pipelines that already understand compose files while adding Bake’s advanced build capabilities.
Cross-Platform Compatibility: Matrix builds enable teams to efficiently manage builds across multiple architectures, OS versions, and dependency combinations from a single configuration.
Dynamic Adaptation: HCL expressions allow builds to adapt to different environments, git branches, or CI variables without maintaining multiple configurations.
Build Optimization: Custom functions enable sophisticated logic for things like version calculation, tag generation, and conditional builds based on git history.
Quality Control: Variable validation and inheritance ensure consistent configuration across complex build scenarios, reducing errors and maintenance burden.
Scale Management: Groups and targets help organize large-scale build systems with dozens or hundreds of permutations, making them manageable and maintainable.
4. Docker Build Cloud
With Bake-optimized builds as the foundation, developers can achieve more efficient Docker Build Cloud performance and faster builds.
Enhanced Docker Build Cloud Performance: Instantly parallelize matrix builds across cloud infrastructure, turning hour-long build pipelines into minutes without managing build infrastructure.
Resource Optimization: Leverage Build Cloud’s distributed caching and deduplication to dramatically reduce bandwidth usage and build times, which is especially valuable for remote teams.
Cost Management: Save cost with DBC — Bake’s precise target definitions mean you only consume cloud resources for exactly what needs to be built.
Developer Experience: Teams can run complex multi-architecture builds without powerful local machines, enabling development from any device while maintaining build performance.
CI/CD Enhancement: Offload resource-intensive builds from CI runners to Build Cloud, reducing CI costs and queue times while improving reliability.
What’s New in Bake for GA?
Docker Bake has been an experimental feature for several years, allowing us to refine and improve it based on user feedback. So, there is already a strong set of ingredients that users love, such as targets and groups, variables, HCL Expression Support, inheritance capabilities, matrix targets, and additional contexts. With this GA release, Bake is now ready for production use, and we’ve added several enhancements to make it more efficient, secure, and easier to use:
Deduplicated Context Transfers: Significantly speeds up build pipelines by eliminating redundant file transfers when multiple targets share the same build context.
Entitlements: Enhances security and resource management by providing fine-grained control over what capabilities and resources builders can access during the build process.
Composable Attributes: Simplifies configuration management by allowing teams to define reusable attribute sets that can be mixed, matched, and overridden across different targets.
Variable Validation: Prevents wasted time and resources by catching configuration errors before the actual build process begins.
Deduplicate context transfers
When you build targets concurrently using groups, build contexts are loaded independently for each target. If the same context is used by multiple targets in a group, that context is transferred once for each time it’s used. This can significantly impact build time, depending on your build configuration.
Previously, the workaround required users to define a named context that loads the context files and then have each target reference the named context. But with Bake, this will be handled automatically now.
Bake can automatically deduplicate context transfers from targets sharing the same context. When you build targets concurrently using groups, build contexts are loaded independently for each target. If the same context is used by multiple targets in a group, that context is transferred once for each time it’s used. This more efficient approach leads to much faster build time.
Read more about how to speed up your build time in our docs.
Entitlements
Bake now includes entitlements to control access to privileged operations, aligning with Build. This prevents unintended side effects and security risks. If Bake detects a potential issue — like a privileged access request or an attempt to access files outside the current directory — the build will fail unless explicitly allowed.
To be consistent, the Bake command now supports the --allow=ENTITLEMENT flag to grant access to additional entitlements. The following entitlements are currently supported for Bake.
Build equivalents
--allow network.host— Allows executions with host networking.
--allow security.insecure— Allows executions without sandbox. (i.e. —privileged)
File system: Grant filesystem access for builds that need access files outside the working directory. This will impact context, output, cache-from, cache-to, dockerfile, secret
--allow fs=<path|*>— Grant read and write access to files outside the working directory.
--allow fs.read=<path|*>— Grant read access to files outside the working directory.
--allow fs.write=<path|*> — Grant write access to files outside the working directory.
ssh
--allow ssh—– Allows exposing SSH agent.
Composable attributes
Several attributes previously had to be defined in CSV (e.g. type=provenance,mode=min). These were challenging to read and couldn’t be easily overridden. The following can now be defined as structured objects:
target "app" {
attest = [
{ type = "provenance", mode = "max" },
{ type = "sbom", disabled = true}
]
cache-from = [
{ type = "registry", ref = "user/app:cache" },
{ type = "local", src = "path/to/cache"}
]
cache-to = [
{ type = "local", dest = "path/to/cache" },
]
output = [
{ type = "oci", dest = "../out.tar" },
{ type = "local", dest="../out"}
]
secret = [
{ id = "mysecret", src = "path/to/secret" },
{ id = "mysecret2", env = "TOKEN" },
]
ssh = [
{ id = "default" },
{ id = "key", paths = ["path/to/key"] },
]
}
As such, the attributes are now composable. Teams can mix, match, and override attributes across different targets which simplifies configuration management.
Bake now supports validation for variables similar to Terraform to help developers catch and resolve configuration errors early. The GA for Bake also supports the following use cases.
Basic validation
To verify that the value of a variable conforms to an expected type, value range, or other condition, you can define custom validation rules using the validation block.
You can reference other Bake variables in your condition expression, enabling validations that enforce dependencies between variables. This ensures that dependent variables are set correctly before proceeding.
variable "FOO" {}
variable "BAR" {
validation {
condition = FOO != ""
error_message = "BAR requires FOO to be set."
}
}
target "default" {
args = {
BAR = BAR
}
}
New Bake options
In addition to updating the Bake configuration, we’ve added a new –list option. Previously, if you were unfamiliar with a project or wanted a reminder of the supported targets and variables, you would have to read through the file. Now, the list option will allow you to quickly query a list of them. It also supports the JSON format option if you need programmatic access.
List target
Quickly get a list of the targets available in your Bake configuration.
These improvements build on a powerful feature set, ensuring Bake is both reliable and future-ready.
Get started with Docker Bake
Ready to simplify your builds? Update to Docker Desktop 4.38 today and start using Bake. With its declarative syntax and advanced features, Docker Bake is here to help you build faster, more efficiently, and with less effort.
Explore the documentation to learn how to create your first Bake file and experience the benefits of streamlined builds firsthand.
At Docker, we’re committed to simplifying the developer experience and empowering enterprises to scale securely and efficiently. With the Docker Desktop 4.38 release, teams can look forward to improved developer productivity and enterprise governance.
We’re excited to announce the General Availability of Bake, a powerful feature for optimizing build performance and multi-node Kubernetes testing to help teams “shift left.” We’re also expanding availability for several enterprise features designed to boost operational efficiency. And last but not least, Docker AI Agent (formerly Project: Agent Gordon) is now in Beta, delivering intelligent, real-time Docker-related suggestions across Docker CLI, Desktop, and Hub. It’s here to help developers navigate Docker concepts, fix errors, and boost productivity.
Docker’s AI Agent boosts developer productivity
We’re thrilled to introduce Docker AI Agent (also known as Project: Agent Gordon) — an embedded, context-aware assistant seamlessly integrated into the Docker suite. Available within Docker Desktop and CLI, this innovative agent delivers real-time, tailored guidance for tasks like container management and Docker-specific troubleshooting — eliminating disruptive context-switching. Docker AI agent can be used for every Docker-related concept and technology, whether you’re getting started, optimizing an existing Dockerfile or Compose file, or understanding Docker technologies in general. By addressing challenges precisely when and where developers encounter them, Docker AI Agent ensures a smoother, more productive workflow.
The first iteration of Docker’s AI Agent is now available in Beta for all signed-in users. The agent is disabled by default, so user activation is required. Read more about Docker’s New AI Agent and how to use it to accelerate developer velocity here.
Figure 1: Asking questions to Docker AI Agent in Docker Desktop
Simplify build configurations and boost performance with Docker Bake
Docker Bake is an orchestration tool that simplifies and speeds up Docker builds. After launching as an experimental feature, we’re thrilled to make it generally available with exciting new enhancements.
While Dockerfiles are great for defining build steps, teams often juggle docker build commands with various options and arguments — a tedious and error-prone process. Bake changes the game by introducing a declarative file format that consolidates all options and image dependencies (also known as targets) in one place. No more passing flags to every build command! Plus, Bake’s ability to parallelize and deduplicate work ensures faster and more efficient builds.
Key benefits of Docker Bake
Simplicity: Abstract complex build configurations into one simple command.
Flexibility: Write build configurations in a declarative syntax, with support for custom functions, matrices, and more.
Consistency: Share and maintain build configurations effortlessly across your team.
Performance: Bake parallelizes multi-image workflows, enabling faster and more efficient builds.
Developers can simplify multi-service builds by integrating Bake directly into their Compose files — Bake supports Compose files natively. It enables easy, efficient building of multiple images from a single repository with shared configurations. Plus, it works seamlessly with Docker Build Cloud locally and in CI. With Bake-optimized builds as the foundation, developers can achieve more efficient Docker Build Cloud performance and faster builds.
Learn more about streamlining build configurations, boosting performance, and improving team workflows with Bake in our announcement blog.
Shift Left with Multi-Node Kubernetes testing in Docker Desktop
In today’s complex production environments, “shifting left” is more essential than ever. By addressing concerns earlier in the development cycle, teams reduce costs and simplify fixes, leading to more efficient workflows and better outcomes. That’s why we continue to bring new features and enhancements to integrate feedback directly into the developer’s inner loop
Docker Desktop now includes Multi-Node Kubernetes integration, enabling easier and extensive testing directly on developers’ machines. While single-node clusters allow for quick verification of app deployments, they fall short when it comes to testing resilience and handling the complex, unpredictable issues of distributed systems. To tackle this, we’re updating our Kubernetes distribution with kind — a lightweight, fast, and user-friendly solution for local test and multi-node cluster simulations.
Figure 2: Selecting Kubernetes version and cluster number for testing
Key Benefits:
Multi-node cluster support: Replicate a more realistic production environment to test critical features like node affinity, failover, and networking configurations.
Multiple Kubernetes versions: Easily test across different Kubernetes versions, which is a must for validating migration paths.
Up-to-date maintenance: Since kind is an actively maintained open-source project, developers can update to the latest version on demand without waiting for the next Docker Desktop release.
Head over to our documentation to discover how to use multi-node Kubernetes clusters for local testing and simulation.
General availability of administration features for Docker Business subscription
With the Docker Desktop 4.36 release, we introduced Beta enterprise admin tools to streamline administration, improve security, and enhance operational efficiency. And the feedback from our Early Access Program customers has been overwhelmingly positive.
For instance, enforcing sign-in with macOS configuration files and across multiple organizations makes deployment easier and more flexible for large enterprises. Also, the PKG installer simplifies managing large-scale Docker Desktop deployments on macOS by eliminating the need to convert DMG files into PKG first.
Today, the features below are now available to all Docker Business customers.
Looking ahead, Docker is dedicated to continue expanding enterprise administration capabilities. Stay tuned for more announcements!
Wrapping up
Docker Desktop 4.38 reinforces our commitment to simplifying the developer experience while equipping enterprises with robust tools.
With Bake now in GA, developers can streamline complex build configurations into a single command. The new Docker AI Agent offers real-time, on-demand guidance within their preferred Docker tools. Plus, with Multi-node Kubernetes testing in Docker Desktop, they can replicate realistic production environments and address issues earlier in the development cycle. Finally, we made a few new admin tools available to all our Business customers, simplifying deployment, management, and monitoring.
We look forward to how these innovations accelerate your workflows and supercharge your operations!
Learn more
Authenticate and update to receive your subscription level’s newest Docker Desktop features.
For years, Docker has been an essential partner for developers, empowering everyone from small startups to the world’s largest enterprises. Today, AI is transforming organizations across industries, creating opportunities for those who embrace it to gain a competitive edge. Yet, for many teams, the question of where to start and how to effectively integrate AI into daily workflows remains a challenge. True to its developer-first philosophy, Docker is here to bridge that gap.
We’re thrilled to introduce the beta launch of Docker AI Agent (also known as Project: Gordon)—an embedded, context-aware assistant seamlessly integrated into the Docker suite. Available within Docker Desktop and CLI, this innovative agent delivers tailored guidance for tasks like building and running containers, authoring Dockerfiles and Docker-specific troubleshooting—eliminating disruptive context-switching. By addressing challenges precisely when and where developers encounter them, Docker AI Agent ensures a smoother, more productive workflow.
As the AI Agent evolves, enterprise teams will unlock even greater capabilities, including customizable features that streamline collaboration, enhance security, and help developers work smarter. With the Docker AI Agent, we’re making Docker even easier and more effective to use than it has ever been — AI accessible, actionable, and indispensable for developers everywhere.
How Docker’s AI Agent Simplifies Development Challenges
Developing in today’s fast-paced tech landscape is increasingly complex, with developers having to learn an ever growing number of tools, libraries and technologies.
By integrating a GenAI Agent into Docker’s ecosystem, we aim to provide developers with a powerful assistant that can help them navigate these complexities.
The Docker AI Agent helps developers accelerate their work, providing real-time assistance, actionable suggestions, and automations that remove many of the manual tasks associated with containerized application development. Delivering the most helpful, expert-level guidance on Docker-related questions and technologies, Gordon serves as a powerful support system for developers, meeting them exactly where they are in their workflow.
If you’re a developer who favors graphical interfaces, Docker Desktop AI UI will help you navigate container running issues, image size management and more generic Dockerfile oriented questions. If you’re a command line interface user, you can call, and share context with the agent directly in your favorite terminal.
So what can Docker’s AI Agent do today?
We’re delivering an expert assistant for every Docker-related concept and technology, whether it’s getting started, optimizing an existing Dockerfile or Compose file, or understanding Docker technologies in general. With Docker AI Agent, you also have the ability to delegate actions while maintaining full control and review over the process.
A first example, if you want to run a container from an image, our agent can suggest the most appropriate docker run command tailored to your needs. This eliminates the guesswork or the need to search Docker Hub, saving you time and effort. The result combines a custom prompt, live data from Docker Hub, Docker container expertise and private usage insights, unique to Docker Inc.
We’ve intentionally designed the output to be concise and actionable, avoiding the overwhelming verbosity often associated with AI-generated commands. We also provide sources for most of the AI agent recommendations, pointing directly to our documentation website. Our goal is to continuously refine this experience, ensuring that Docker’s AI Agent always provides the best possible command based on your specific local context.
Beside helping you run containers, the Docker AI Agent can today:
Explain, Rate and optimize Dockerfile leveraging the latest version of Docker.
Help you run containers in an effective, concise way, leveraging the local context (checking port already used or volumes).
Answers any docker related questions with the latest version of our documentations for our whole tool suite, and as such is able to answer any kind of questions on Docker tools and technologies.
Containerize a software project helping you run your software in containers.
Helps on Docker related Github Actions.
Suggest fix when a container is failing to start in Docker Desktop.
Provides contextual help for containers, images and volumes.
Can augment its answer with per directory MCP servers (see doc).
For the node expert, in the above screenshot the AI is recommending node 20.12 which is not the latest version but the one the AI found in the package.json.
With every future version of Docker Desktop and thanks to the feedback that you provide, the agent will be able to do so much more in the future.
How can you try Docker AI Agent?
This first beta release of Docker AI Agent is now progressively available for all signed-in users*. By default, the Docker AI agent is disabled. To enable it you will need to follow the steps below. Here’s how to get started:
Install or update to the latest release of Docker Desktop 4.38
Enable Docker AI into Docker Desktop Settings -> Features in Development
For the best experience, ensure the Docker terminal is enabled by going to Settings → General
Apply Changes
* If you’re a business subscriber, your Administrator needs to enable the Docker AI Agent for the organization first. This can be done through the Settings Management. If this is your case, feel free to contact us through the support for further information.
Docker Agent’s Vision for 2025
By 2025, we aim to expand the agent’s capabilities with features like customizing your experience with more context from your registry, enhanced GitHub Copilot integrations, and deeper presence across the development tools you already use. With regular updates and your feedback, Docker AI Agent is being built to become an indispensable part of your development process.
For now this beta is the start of an exciting evolution in how we approach developer productivity. Stay tuned for more updates as we continue to shape a smarter, more streamlined way to build, secure, and ship applications. We want to hear from you, if you like or want more information you can contact us.
Nearly half (45%) of developers say they don’t have enough time for learning and development, according to a developer experience research study by Harness and Wakefield Research. Additionally, developer onboarding is a slow and painful process, with 71% of executive buyers saying that onboarding new developers takes at least two months.
To accelerate innovation and bring products to market faster, organizations must empower developers with robust support and intuitive guardrails, enabling them to succeed within a structured yet flexible environment. That’s where Docker fits in: We help developers onboard quickly and help organizations set up the right guardrails to give developers the flexibility to innovate within the boundaries of company policies.
Setting up developer teams for success
Docker is recognized as one of the most used, desired, and admired developer tools, making it an essential component of any development team’s toolkit. For developers who are new to Docker, you can quickly get them up and running with Docker’s integrated development workflows, verified secure content, and accessible learning resources and community support.
Streamlined developer onboarding
When new developers join a team, Docker Desktop can significantly reduce the time and effort required to set up their development environments. Docker Desktop integrates seamlessly with popular IDEs, such as Visual Studio Code, allowing developers to containerize directly within familiar tools, accelerating learning within their usual workflows. Docker Extensions expand Docker Desktop’s capabilities and establish new functionalities, integrating developers’ favorite development tools into their application development and deployment workflows.
Developers can also use Docker for GitHub Copilot for seamless onboarding with assistance for containerizing applications, generating Docker assets, and analyzing project vulnerabilities. In fact, the Docker extension is a top choice among developers in GitHub Copilot’s extension leaderboard, as highlighted by Visual Studio Magazine.
Docker Build Cloud integrates with Docker Compose and CI workflows, making it a seamless transition for dev teams. Verified content on Docker Hub gives developers preconfigured, trusted images, reducing setup time and ensuring a secure foundation as they onboard onto projects.
Docker Scout provides actionable insights and recommendations, allowing developers to enhance their container security awareness, scan for vulnerabilities, and improve security posture with real-time feedback. And, Testcontainers Cloud lets developers run reliable integration tests, with real dependencies defined in code. With these tools, developers can be confident about delivering high-quality and reliable apps and experiences in production.
Continuous learning with accessible knowledge resources
Continuous learning is a priority for Docker, with a wide range of accessible resources and tools designed to help developers deepen their knowledge and stay current in their containerization journey.
Docker Docs offers beginner-friendly guides, tutorials, and AI tools to guide developers through foundational concepts, empowering them to quickly build their container skills. Our collection of guides takes developers step by step to learn how Docker can optimize development workflows and how to use it with specific languages, frameworks, or technologies.
Docker Hub’s AI Catalog empowers developers to discover, pull, and integrate AI models into their workflows, bridging the gap between innovation and implementation.
Docker also offers regular webinars and tech talks that help developers stay updated on new features and best practices and provide a platform to discuss real-world challenges. If you’re a Docker Business customer, you can even request additional, customized training from our Docker experts.
Docker’s partnerships with educational platforms and organizations, such as Udemy Training and LinkedIn Learning, ensure developers have access to comprehensive training — from beginner tutorials to advanced containerization topics.
Docker’s global developer community
One of Docker’s greatest strengths is its thriving global developer community, offering organizations a unique advantage by connecting them with a wealth of shared expertise, resources, and real-world solutions.
With more than 20 million monthly active users, Docker’s community forums and events foster vibrant collaboration, giving developers access to a collective knowledge base that spans industries and expertise levels. Developers can ask questions, solve challenges, and gain insights from a diverse range of peers — from beginners to seasoned experts. Whether you’re troubleshooting an issue or exploring best practices, the Docker community ensures you’re never working in isolation.
A key pillar of this ecosystem is the Docker Captains program — a network of experienced and passionate Docker advocates who are leaders in their fields. Captains share technical knowledge through blog posts, videos, webinars, and workshops, giving businesses and teams access to curated expertise that accelerates onboarding and productivity.
Beyond forums and the Docker Captains program, Docker’s community-driven events, such as meetups and virtual workshops (Figure 1), provide developers with direct access to real-world use cases, innovative workflows, and emerging trends. These interactions foster continuous learning and help developers and their organizations keep pace with the ever-evolving software development landscape.
Figure 1: Docker DevTools Day 1.0 Meetup in Singapore.
For businesses, tapping into Docker’s extensive community means access to a vast pool of knowledge, support, and inspiration, which is a critical asset in driving developer productivity and innovation.
Empowering developers with enhanced user management and security
To scale and standardize app development processes across the entire company, you also need to have the right guardrails in place for governance, compliance, and security, which is often handled through enterprise control and admin management tools. Ideally, organizations provide guardrails without being overly prescriptive and slowing developer productivity and innovation.
Modern enterprises require a layered security approach, beginning with trusted content as the foundation for building robust and compliant applications. This approach gives your dev teams a good foundation for building securely from the start.
Throughout the software development process, you need a secure platform. For regulated industries like finance and public sectors, this means fortified dev environments. Security vulnerability analysis and policy evaluation tools also help inform improvements and remediation.
Additionally, you need enterprise controls and dashboards that ensure enterprise IT and security teams can confidently monitor and manage risk.
Setting up the right guardrails
Docker provides a number of admin tools to safeguard your software with integrated container security in the Docker Business plan. Our goal is to improve security and compliance of developer environments with minimal impact on developer experience or productivity.
Centralized settings for improved dev environments security
With a solid foundation to build securely from the start, your organization can further enhance security throughout the software development process. Docker ensures software supply chain integrity through vulnerability scanning and image analysis with Docker Scout. Rapid remediation capabilities paired with detailed CVE reporting help developers quickly find and fix vulnerabilities, resulting in speedy time to resolution.
Although containers are generally secure, container development tools still must be properly secured to reduce the risk of security breaches in the developer’s environment. Hardened Docker Desktop is an example of Docker’s fortified development environments with enhanced container isolation. It lets you enforce strict security settings and prevent developers and their containers from bypassing these controls. With air-gapped containers, you can further restrict containers from accessing network resources, limiting where data can be uploaded to or downloaded from.
Continuous monitoring and managing risks
With the Admin Console and Docker Desktop Insights, IT administrators and security teams can visualize and understand how Docker is used within their organizations and manage the implementation of organizational configurations and policies (Figure 2).
These insights help teams streamline processes and improve efficiency. For example, you can enforce sign-in for developers who don’t sign in to an account associated with your organization. This step ensures that developers receive the benefits of your Docker subscription and work within the boundaries of the company policies.
Figure 2: Docker Desktop Insights Dashboard provides information on product usage.
For business and engineering leaders, full visibility and governance over the development process help ensure compliance and mitigate risk while driving developer productivity.
Unlock innovation with Docker’s development suite
Docker is the leading suite of tools purpose-built for cloud-native development, combining a best-in-class developer experience with enterprise-grade security and governance. With Docker, your organization can streamline onboarding, foster innovation, and maintain robust compliance — all while empowering your teams to deliver impactful solutions to market faster and more securely.
Explore the Docker Business plan today and unlock the full potential of your development processes.
We’ve heard from our community about the limited number of compatible add-on modules for our tiny but powerful Seeed Studio XIAO boards. Starting 2025, we’re addressing this by developing more XIAO add-ons!
For our first product collection of the year, we’re introducing a new relay, ePaper Driver Board, expansion board, and sensor – all compatible with Seeed Studio XIAO boards!
Standard XIAO add-on dimension (which is the triple size of a XIAO board)
Don’t worry – we’ll keep both versions available to suit different application needs. Currently, this new ePaper Driver Board is available for pre-order at $4.9, with estimated shipping at the end of January 2025.
Need to control DC appliances from your XIAO? This single-channel 5V Relay Add-on Module for XIAO handles all the control with DC. With snap-on compatibility for pre-soldered XIAO boards and screw terminals, no soldering is required! The HF32FA-G relay makes it perfect for IoT and home automation. P.S. Our team also designed a 3D enclosure for this relay add-on with an XIAO dev board and open sourced it on Thingiverse for you to remix.
Compatibility: all Seeed Studio XIAO Pre-Soldered Dev Boards (battery voltage monitoring unavailable for XIAO SAMD21 and XIAO RP2040)
Looking for a thumb-size temperature, humidity and light sensor? XIAO Logger Hat gets you covered. Created by Westlake University’s Marcel and scaled through Fusion Co-Create, this thumb-sized environmental sensor includes SHT40 temperature, humidity, and BH1750 light sensors, plus RTC and battery voltage monitoring.
XIAO PowerBread, a Breadboard Power Supply and Meter
Designed by Nicho D through Seeed Fusion Co-Create, XIAO PowerBread is a compact breadboard power supply with built-in monitoring. It provides stable 3.3V and 5V outputs with real-time voltage, current, and power tracking on its LCD display. It’s open-source with comprehensive documentation and customizable code.
That’s our new product roundup! Tell us which product interests you most or share your suggestions. Want to influence our future products? Join the discussion on our Seeed Studio XIAO Open Roadmap – your input shapes what we build next.
Until next time!
Notes at the end.
Hey community, we’re curating a monthly newsletter centering around the beloved Seeed Studio XIAO. If you want to stay up-to-date with:
Cool Projects from the Community to get inspiration and tutorials Product Updates: firmware update, new product spoiler Wiki Updates: new wikis + wiki contribution News: events, contests, and other community stuff
Hey there, fellow engineers and tech enthusiasts! I’m excited to share one of my favorite strategies for modern software delivery: combining Docker and Jenkins to power up your CI/CD pipelines.
Throughout my career as a Senior DevOps Engineer and Docker Captain, I’ve found that these two tools can drastically streamline releases, reduce environment-related headaches, and give teams the confidence they need to ship faster.
In this post, I’ll walk you through what Docker and Jenkins are, why they pair perfectly, and how you can build and maintain efficient pipelines. My goal is to help you feel right at home when automating your workflows. Let’s dive in.
Brief overview of continuous integration and continuous delivery
Continuous integration (CI) and continuous delivery (CD) are key pillars of modern development. If you’re new to these concepts, here’s a quick rundown:
Continuous integration (CI): Developers frequently commit their code to a shared repository, triggering automated builds and tests. This practice prevents conflicts and ensures defects are caught early.
Continuous delivery (CD): With CI in place, organizations can then confidently automate releases. That means shorter release cycles, fewer surprises, and the ability to roll back changes quickly if needed.
Leveraging CI/CD can dramatically improve your team’s velocity and quality. Once you experience the benefits of dependable, streamlined pipelines, there’s no going back.
Why combine Docker and Jenkins for CI/CD?
Docker allows you to containerize your applications, creating consistent environments across development, testing, and production. Jenkins, on the other hand, helps you automate tasks such as building, testing, and deploying your code. I like to think of Jenkins as the tireless “assembly line worker,” while Docker provides identical “containers” to ensure consistency throughout your project’s life cycle.
Here’s why blending these tools is so powerful:
Consistent environments: Docker containers guarantee uniformity from a developer’s laptop all the way to production. This consistency reduces errors and eliminates the dreaded “works on my machine” excuse.
Speedy deployments and rollbacks: Docker images are lightweight. You can ship or revert changes at the drop of a hat — perfect for short delivery process cycles where minimal downtime is crucial.
Scalability: Need to run 1,000 tests in parallel or support multiple teams working on microservices? No problem. Spin up multiple Docker containers whenever you need more build agents, and let Jenkins orchestrate everything with Jenkins pipelines.
For a DevOps junkie like me, this synergy between Jenkins and Docker is a dream come true.
Setting up your CI/CD pipeline with Docker and Jenkins
Before you roll up your sleeves, let’s cover the essentials you’ll need:
Docker Desktop (or a Docker server environment) installed and running. You can get Docker for various operating systems.
Jenkins downloaded from Docker Hub or installed on your machine. These days, you’ll want jenkins/jenkins:lts (the long-term support image) rather than the deprecated library/jenkins image.
Proper permissions for Docker commands and the ability to manage Docker images on your system.
A GitHub or similar code repository where you can store your Jenkins pipeline configuration (optional, but recommended).
Pro tip: If you’re planning a production setup, consider a container orchestration platform like Kubernetes. This approach simplifies scaling Jenkins, updating Jenkins, and managing additional Docker servers for heavier workloads.
Building a robust CI/CD pipeline with Docker and Jenkins
After prepping your environment, it’s time to create your first Jenkins-Docker pipeline. Below, I’ll walk you through common steps for a typical pipeline — feel free to modify them to fit your stack.
1. Install necessary Jenkins plugins
Jenkins offers countless plugins, so let’s start with a few that make configuring Jenkins with Docker easier:
Docker Pipeline Plugin
Docker
CloudBees Docker Build and Publish
How to install plugins:
Open Manage Jenkins > Manage Plugins in Jenkins.
Click the Available tab and search for the plugins listed above.
Pro tip (advanced approach): If you’re aiming for a fully infrastructure-as-code setup, consider using Jenkins configuration as code (JCasC). With JCasC, you can declare all your Jenkins settings — including plugins, credentials, and pipeline definitions — in a YAML file. This means your entire Jenkins configuration is version-controlled and reproducible, making it effortless to spin up fresh Jenkins instances or apply consistent settings across multiple environments. It’s especially handy for large teams looking to manage Jenkins at scale.
In this step, you’ll define your pipeline. A Jenkins “pipeline” job uses a Jenkinsfile (stored in your code repository) to specify the steps, stages, and environment requirements.
Now that your pipeline is set up, you’ll want Jenkins to run it automatically:
Webhook triggers: Configure your source control (e.g., GitHub) to send a webhook whenever code is pushed. Jenkins will kick off a build immediately.
Poll SCM: Jenkins periodically checks your repo for new commits and starts a build if it detects changes.
Which trigger method should you choose?
Webhook triggers are ideal if you want near real-time builds. As soon as you push to your repo, Jenkins is notified, and a new build starts almost instantly. This approach is typically more efficient, as Jenkins doesn’t have to continuously check your repository for updates. However, it requires that your source control system and network environment support webhooks.
Poll SCM is useful if your environment can’t support incoming webhooks — for example, if you’re behind a corporate firewall or your repository isn’t configured for outbound hooks. In that case, Jenkins routinely checks for new commits on a schedule you define (e.g., every five minutes), which can add a small delay and extra overhead but may simplify setup in locked-down environments.
Personal experience: I love webhook triggers because they keep everything as close to real-time as possible. Polling works fine if webhooks aren’t feasible, but you’ll see a slight delay between code pushes and build starts. It can also generate extra network traffic if your polling interval is too frequent.
4. Build, test, and deploy with Docker containers
Here comes the fun part — automating the entire cycle from build to deploy:
Build Docker image: After pulling the code, Jenkins calls docker.build to create a new image.
Run tests: Automated or automated acceptance testing runs inside a container spun up from that image, ensuring consistency.
Push to registry: Assuming tests pass, Jenkins pushes the tagged image to your Docker registry— this could be Docker Hub or a private registry.
Deploy: Optionally, Jenkins can then deploy the image to a remote server or a container orchestrator (Kubernetes, etc.).
This streamlined approach ensures every step — build, test, deploy — lives in one cohesive pipeline, preventing those “where’d that step go?” mysteries.
5. Optimize and maintain your pipeline
Once your pipeline is up and running, here are a few maintenance tips and enhancements to keep everything running smoothly:
Clean up images: Routine cleanup of Docker images can reclaim space and reduce clutter.
Security updates: Stay on top of updates for Docker, Jenkins, and any plugins. Applying patches promptly helps protect your CI/CD environment from vulnerabilities.
Resource monitoring: Ensure Jenkins nodes have enough memory, CPU, and disk space for builds. Overworked nodes can slow down your pipeline and cause intermittent failures.
Pro tip: In large projects, consider separating your build agents from your Jenkins controller by running them in ephemeral Docker containers (also known as Jenkins agents). If an agent goes down or becomes stale, you can quickly spin up a fresh one — ensuring a clean, consistent environment for every build and reducing the load on your main Jenkins server.
Why use Declarative Pipelines for CI/CD?
Although Jenkins supports multiple pipeline syntaxes, Declarative Pipelines stand out for their clarity and resource-friendly design. Here’s why:
Simplified, opinionated syntax: Everything is wrapped in a single pipeline { ... } block, which minimizes “scripting sprawl.” It’s perfect for teams who want a quick path to best practices without diving deeply into Groovy specifics.
Easier resource allocation: By specifying an agent at either the pipeline level or within each stage, you can offload heavyweight tasks (builds, tests) onto separate worker nodes or Docker containers. This approach helps prevent your main Jenkins controller from becoming overloaded.
Parallelization and matrix builds: If you need to run multiple test suites or support various OS/browser combinations, Declarative Pipelines make it straightforward to define parallel stages or set up a matrix build. This tactic is incredibly handy for microservices or large test suites requiring different environments in parallel.
Built-in “escape hatch”: Need advanced Groovy features? Just drop into a script block. This lets you access Scripted Pipeline capabilities for niche cases, while still enjoying Declarative’s streamlined structure most of the time.
Cleaner parameterization: Want to let users pick which tests to run or which Docker image to use? The parameters directive makes your pipeline more flexible. A single Jenkinsfile can handle multiple scenarios — like unit vs. integration testing — without duplicating stages.
Declarative Pipeline examples
Below are sample pipelines to illustrate how declarative syntax can simplify resource allocation and keep your Jenkins controller healthy.
Using Declarative Pipelines helps ensure your CI/CD setup is easier to maintain, scalable, and secure. By properly configuring agents — whether Docker-based or label-based — you can spread workloads across multiple worker nodes, minimize resource contention, and keep your Jenkins controller humming along happily.
Best practices for CI/CD with Docker and Jenkins
Ready to supercharge your setup? Here are a few tried-and-true habits I’ve cultivated:
Leverage Docker’s layer caching: Optimize your Dockerfiles so stable (less frequently changing) layers appear early. This drastically reduces build times.
Run tests in parallel: Jenkins can run multiple containers for different services or microservices, letting you test them side by side. Declarative Pipelines make it easy to define parallel stages, each on its own agent.
Shift left on security: Integrate security checks early in the pipeline. Tools like Docker Scout let you scan images for vulnerabilities, while Jenkins plugins can enforce compliance policies. Don’t wait until production to discover issues.
Optimize resource allocation: Properly configure CPU and memory limits for Jenkins and Docker containers to avoid resource hogging. If you’re scaling Jenkins, distribute builds across multiple worker nodes or ephemeral agents for maximum efficiency.
Configuration management: Store Jenkins jobs, pipeline definitions, and plugin configurations in source control. Tools like Jenkins Configuration as Code simplify versioning and replicating your setup across multiple Docker servers.
With these strategies — plus a healthy dose of Declarative Pipelines — you’ll have a lean, high-octane CI/CD pipeline that’s easier to maintain and evolve.
Troubleshooting Docker and Jenkins Pipelines
Even the best systems hit a snag now and then. Here are a few hurdles I’ve seen (and conquered):
Handling environment variability: Keep Docker and Jenkins versions synced across different nodes. If multiple Jenkins nodes are in play, standardize Docker versions to avoid random build failures.
Troubleshooting build failures: Use docker logs -f <container-id> to see exactly what happened inside a container. Often, the logs reveal missing dependencies or misconfigured environment variables.
Networking challenges: If your containers need to talk to each other — especially across multiple hosts — make sure you configure Docker networks or an orchestration platform properly. Read Docker’s networking documentation for details, and check out the Jenkins diagnosing issues guide for more troubleshooting tips.
Conclusion
Pairing Docker and Jenkins offers a nimble, robust approach to CI/CD. Docker locks down consistent environments and lightning-fast rollouts, while Jenkins automates key tasks like building, testing, and pushing your changes to production. When these two are in harmony, you can expect shorter release cycles, fewer integration headaches, and more time to focus on developing awesome features.
A healthy pipeline also means your team can respond quickly to user feedback and confidently roll out updates — two crucial ingredients for any successful software project. And if you’re concerned about security, there are plenty of tools and best practices to keep your applications safe.
I hope this guide helps you build (and maintain) a high-octane CI/CD pipeline that your team will love. If you have questions or need a hand, feel free to reach out on the community forums, join the conversation on Slack, or open a ticket on GitHub issues. You’ll find plenty of fellow Docker and Jenkins enthusiasts who are happy to help.
Without continuous improvement in software security, you’re not standing still — you’re walking backward into oncoming traffic. Attack vectors multiply, evolve, and look for the weakest link in your software supply chain daily.
Cybersecurity Ventures forecasts that the global cost of software supply chain attacks will reach nearly $138 billion by 2031, up from $60 billion in 2025 and $46 billion in 2023. A single overlooked vulnerability isn’t just a flaw; it’s an open invitation for compromise, potentially threatening your entire system. The cost of a breach doesn’t stop with your software — it extends to your reputation and customer trust, which are far harder to rebuild.
In this post, we’ll explore how these tools provide built-in security, governance, and visibility, helping your team innovate faster while staying protected.
Securing the supply chain
Your software supply chain isn’t just an automated sequence of tools and processes. It’s a promise — to your customers, team, and future. Promises are fragile. The cracks can start to show with every dependency, third-party integration, and production push. Tools like Image Access Management help protect your supply chain by providing granular control over who can pull, share, or modify images, ensuring only trusted team members access sensitive assets. Meanwhile, Hardened Docker Desktop ensures developers work in a secure, tamper-proof environment, giving your team confidence that development is aligned with enterprise security standards. The solution isn’t to slow down or second-guess; it’s to continuously improve on securing your software supply chain, such as automated vulnerability scans and trusted content from Docker Hub.
A breach is more than a line item in the budget. Customers ask themselves, “If they couldn’t protect this, what else can’t they protect?” Downtime halts innovation as fines for compliance failures and engineering efforts re-route to forensic security analysis. The brand you spent years perfecting could be reduced to a cautionary tale. Regardless of how innovative your product is, it’s not trusted if it’s not secure.
Organizations must stay prepared by regularly updating their security measures and embracing new technologies to outpace evolving threats. As highlighted in the article Rising Tide of Software Supply Chain Attacks: An Urgent Problem, software supply chain attacks are increasingly targeting critical points in development workflows, such as third-party dependencies and build environments. High-profile incidents like the SolarWinds attack have demonstrated how adversaries exploit trust relationships and weaknesses in widely used components to cause widespread damage.
Preventing security problems from the start
Preventing attacks like the SolarWinds breach requires prioritizing code integrity and adopting secure software development practices. Tools like Docker Scout seamlessly integrate security into developers’ workflows, enabling proactive identification of vulnerabilities in dependencies and ensuring that trusted components form the backbone of your applications.
Docker Hub’s trusted content and Docker Scout’s policy evaluation features help ensure that your organization uses compliant and secure images. Docker Official Images (DOI) provide a robust foundation for deployments, mitigating risks from untrusted components. To extend this security foundation, Image Access Management allows teams to enforce image-sharing policies and restrict access to sensitive components, preventing accidental exposure or misuse. For local development, Hardened Docker Desktop ensures that developers operate in a secure, enterprise-grade environment, minimizing risks from the outset. This combination of tools enables your engineering team to put out fires and, more importantly, prevent them from starting in the first place.
Building guardrails
Governance isn’t a roadblock; it’s the blueprint for progress. The problem is that some companies treat security like a fire extinguisher — something you grab when things go wrong. That is not a viable strategy in the long run. Real innovation happens when security guardrails are so well-designed that they feel like open highways, empowering teams to move fast without compromising safety.
A structured policy lifecycle loop — mapping connections, planning changes, deploying cleanly, and retiring the dead weight — turns governance into your competitive edge. Automate it, and you’re not just checking boxes; you’re giving your teams the freedom to move fast and trust the road ahead.
Continuous improvement on security policy management doesn’t have to feel like a bureaucratic chokehold. Docker provides a streamlined workflow to secure your software supply chain effectively. Docker Scout integrates seamlessly into your development lifecycle, delivering vulnerability scans, image analysis, and detailed reports and recommendations to help teams address issues before code reaches production.
With the introduction of Docker Health Scores — a security grading system for container images — teams gain a clear and actionable snapshot of their image security posture. These scores empower developers to prioritize remediation efforts and continuously improve their software’s security from code to production.
Keeping up with continuous improvement
Security threats aren’t slowing down. New attack vectors and vulnerabilities grow every day. With cybercrime costs expected to rise from $9.22 trillion in 2024 to $13.82 trillion by 2028, organizations face a critical choice: adapt to this evolving threat landscape or risk falling behind, exposing themselves to escalating costs and reputational damage. Continuous improvement in software security isn’t a luxury. Building and maintaining trust with your customers is essential so they know that every fresh deployment is better than the one that came before. Otherwise, expect high costs due to imminent software supply chain attacks.
Best practices for securing the software supply chain involve integrating vulnerability scans early in the development lifecycle, leveraging verified content from trusted sources, and implementing governance policies to ensure consistent compliance standards without manual intervention. Continuous monitoring of vulnerabilities and enforcing runtime policies help maintain security at scale, adapting to the dynamic nature of modern software ecosystems.
Start today
Securing your software supply chain is a journey of continuous improvement. With Docker’s tools, you can empower your teams to build and deploy software securely, ensuring vulnerabilities are addressed before they become liabilities.
Don’t wait until vulnerabilities turn into liabilities. Explore Docker Hub, Docker Scout, Hardened Docker Desktop, and Image Access Management to embed security into every stage of development. From granular control over image access to tamper-proof local environments, Docker’s suite of tools helps safeguard your innovation, protect your reputation, and empower your organization to thrive in a dynamic ecosystem.
Learn more
Docker Scout: Integrates seamlessly into your development lifecycle, delivering vulnerability scans, image analysis, and actionable recommendations to address issues before they reach production.
Docker Health Scores: A security grading system for container images, offering teams clear insights into their image security posture.
Docker Hub: Access trusted, verified content, including Docker Official Images (DOI), to build secure and compliant software applications.
Docker Official Images (DOI): A curated set of high-quality images that provide a secure foundation for your containerized applications.
Image Access Management (IAM): Enforce image-sharing policies and restrict access to sensitive components, ensuring only trusted team members access critical assets.
Hardened Docker Desktop: A tamper-proof, enterprise-grade development environment that aligns with security standards to minimize risks from local development.
This ongoing Docker Labs GenAI series explores the exciting space of AI developer tools. At Docker, we believe there is a vast scope to explore, openly and without the hype. We will share our explorations and collaborate with the developer community in real time. Although developers have adopted autocomplete tooling like GitHub Copilot and use chat, there is significant potential for AI tools to assist with more specific tasks and interfaces throughout the entire software lifecycle. Therefore, our exploration will be broad. We will be releasing software as open source so you can play, explore, and hack with us, too.
After restarting Claude Desktop, you can ask Claude to take a screenshot of any URL using a Headless Chromium browser running in Docker.
You can do the same thing for a Model Context Protocol (MCP) server that you’ve written. You will then be able to distribute this server to your users without requiring them to have anything besides Docker Desktop.
How to create an MCP server Docker Image
An MCP server can be written in any language. However, most of the examples, including the set of reference servers from Anthropic, are written in either Python or TypeScript and use one of the official SDKs documented on the MCP site.
For typical uv-based Python projects (projects with a pyproject.toml and uv.lock in the root), or npm TypeScript projects, it’s simple to distribute your server as a Docker image.
If you don’t already have Docker Desktop, sign up for a free Docker Personal subscription so that you can push your images to others.
Run docker login from your terminal.
Copy either this npm Dockerfile or this Python Dockerfile template into the root of your project. The Python Dockerfile will need at least one update to the last line.
Run the build with the Docker CLI (instructions below).
The two Dockerfiles shown above are just templates. If your MCP server includes other runtime dependencies, you can update the Dockerfiles to include these additions. The runtime of your MCP server should be self-contained for easy distribution.
If you don’t have an MCP server ready to distribute, you can use a simple mcp-hello-world project to practice. It’s a simple Python codebase containing a server with one tool call. Get started by forking the repo, cloning it to your machine, and then following the following instructions to build the MCP server image.
Building the image
Most sample MCP servers are still designed to run locally (on the same machine as the MCP client, communication over stdio). Over the next few months, you’ll begin to see more clients supporting remote MCP servers but for now, you need to plan for your server running on at least two different architectures (amd64 and arm64). This means that you should always distribute what we call multi-platform images when your target is local MCP servers. Fortunately, this is easy to do.
Create a multi-platform builder
The first step is to create a local builder that will be able to build both platforms. Don’t worry; this builder will use emulation to build the platforms that you don’t have. See the multi-platform documentation for more details.
Once the image is pushed, your users will be able to attach your MCP server to Claude Desktop by adding an entry to claude_desktop_config.json that looks something like:
This is a minimal set of arguments. You may want to pass in additional command-line arguments, environment variables, or volume mounts.
Next steps
The MCP protocol gives us a standard way to extend AI applications. Make sure your extension is easy to distribute by packaging it as a Docker image. Check out the Docker Hub mcp namespace for examples that you can try out in Claude Desktop today.
As always, feel free to follow along in our public repo.
This demo will use the Puppeteer MCP server to take a screenshot of a website and invert the colors using Claude Desktop and Docker Desktop. Doing this witho...
This ongoing Docker Labs GenAI series explores the exciting space of AI developer tools. At Docker, we believe there is a vast scope to explore, openly and without the hype. We will share our explorations and collaborate with the developer community in real time. Although developers have adopted autocomplete tooling like GitHub Copilot and use chat, there is significant potential for AI tools to assist with more specific tasks and interfaces throughout the entire software lifecycle. Therefore, our exploration will be broad. We will be releasing software as open source so you can play, explore, and hack with us, too.
In previous articles, we focused on how AI-based tools can help developers streamline tasks and offered ideas for enabling agentic workflows, like reviewing branches and understanding code changes.
In this article, we’ll explore our experiments around the idea of creating a Docker AI Agent — something that could both help new users learn about our tools and products and help power users get things done faster.
During our explorations around this Docker Agent and AI-based tools, we noticed that the main pain points we encountered were often the same:
LLMs need good context to provide good answers (garbage in -> garbage out).
Using AI tools often requires context switching (moving to another app, to a different website, etc.).
We’d like agents to be able to suggest and perform actions on behalf of the users.
Direct product integrations with AI are often more satisfying to use than chat interfaces.
At first, we tried to see what’s possible using off-the-shelf services like ChatGPT or Claude.
By using testing prompts such as “optimize the following Dockerfile, following all best practices” and providing the model with a sub-par but common Dockerfile, we could sometimes get decent answers. Often, though, the resulting Dockerfile had subtle bugs, hallucinations, or simply wasn’t optimized or didn’t use many of the best practices we would’ve hoped for. Thus, this approach was not reliable enough.
Data ended up being the main issue. Training data for LLM models is always outdated by some amount of time, and the number of bad Dockerfiles that you can find online vastly outnumbers the amount of up-to-date Dockerfiles using all best practices, etc.
After doing proof-of-concept tests using a RAG approach, including some documents with lots of useful advice for creating good Dockerfiles, we realized that the AI Agent idea was definitely possible. However, setting up all the things required for a good RAG would’ve taken too much bandwidth from our small team.
Because of this, we opted to use kapa.ai for that specific part of our agent. Docker already uses them to provide the AI docs assistant on Docker docs, so most of our high-quality documentation is already available for us to reference as part of our LLM usage through their service. Using kapa.ai allowed us to experiment more, getting high-quality results faster, and allowing us to try different ideas around the AI agent concept.
Enter Gordon
Out of this experimentation came a new product that you can try: Gordon. With Gordon, we’d like to tackle these pain points. By integrating Gordon into Docker Desktop and the Docker CLI (Figure 1), we can:
Access much more context that can be used by the LLMs to best understand the user’s questions and provide better answers or even perform actions on the user’s behalf.
Be where the users are. If you launch a container via Docker Desktop and it fails, you can quickly debug with Gordon. If you’re in the terminal hacking away, Docker AI will be there, too.
Avoid being a purely chat-based agent by providing Gordon-based features directly as part of Docker Desktop UI elements. If Gordon detects certain scenarios, like a container that failed to start, a button will appear in the UI to directly get suggestions, or run actions, etc. (Figure 2).
Figure 1: Gordon icon on Docker Desktop.Figure 2: Ask Gordon (beta).
What Gordon can do
We want to start with Gordon by optimizing for Docker-related tasks — not general-purpose questions — but we are not excluding expanding the scope to more development-related tasks as work on the agent continues.
Work on Gordon is at an early stage and its capabilities are constantly evolving, but it’s already really good at some things (Figure 3). Here are things to definitely try out:
Ask general Docker-related questions. Gordon knows Docker well and has access to all of our documentation.
Get help debugging container build or runtime errors.
Get help optimizing Docker-related files and configurations.
Ask it how to run specific containers (e.g., “How can I run MongoDB?”).
Figure 3: Using Gordon to understand a Dockerfile.
How Gordon works
The Gordon backend lives on Docker servers, while the client is a CLI that lives on the user’s machine and is bundled with Docker Desktop. Docker Desktop uses the CLI to access the local machine’s files, asking the user for the directory each time it needs that context to answer a question. When using the CLI directly, it has access to the working directory it’s executed in. For example, if you are in a directory with a Dockerfile and you run “Docker AI, rate my Dockerfile”, it will find the one that’s present in that directory
Currently, Gordon does not have write access to any files, so it will not edit any of your files. We’re hard at work on future features that will allow the agent to do the work for you, instead of only suggesting solutions.
Figure 4 shows a rough overview of how we are thinking about things behind the scenes.
Figure 4: Overview of Gordon.
The first step of this pipeline, “Understand the user’s input and figure out which action to perform”, is done using “tool calling” (also known as “function calling”) with the OpenAI API.
Although this is a popular approach, we noticed that the documentation online isn’t very good, and general best practices aren’t well defined yet. This led us to experiment a lot with the feature and try to figure out what works for us and what doesn’t.
Things we noticed:
Tool descriptions are important, and we should prefer more in-depth descriptions with examples.
Testing around tool-detection code is also important. Adding new tools to a request could confuse the LLM and cause it to no longer trigger the expected tool.
The LLM model used influences how the whole tool calling functionality should be implemented, as different models might prefer descriptions written in a certain way, behave better/worse under certain scenarios (e.g. when using lots of tools), etc.
Try Gordon for yourself
Gordon is available as an opt-in Beta feature starting with Docker Desktop version 4.37. To participate in the closed beta, all you need to do is fill out the form on the site.
Initially, Gordon will be available for use both in Docker Desktop and the Docker CLI, but our idea is to surface parts of this tech in various other parts of our products as well.
For more on what we’re doing at Docker, subscribe to our newsletter.
The need for secure and high quality software becomes more critical every day as the impact of vulnerabilities increases and related costs continue to rise. For example, flawed software cost the U.S. economy $2.08 trillion in 2020 alone, according to the Consortium for Information and Software Quality (CISQ). And, a software defect that might cost $100 to fix if found early in the development process can grow exponentially to $10,000 if discovered later in production.
Docker helps you deliver secure, efficient applications by providing consistent environments and fast, reliable container management, building on best practices that let you discover and resolve issues earlier in the software development life cycle (SDLC).
Shifting left to ensure fewer defects
In a previous blog post, we talked about using the right tools, including Docker’s suite of products to boost developer productivity. Besides having the right tools, you also need to implement the right processes to optimize your software development and improve team productivity.
The software development process is typically broken into two distinct loops, the inner and the outer loops. At Docker, we believe that investing in the inner loop is crucial. This means shifting security left and identifying problems as soon as you can. This approach improves efficiency and reduces costs by helping teams find and fix software issues earlier.
Using Docker tools to adopt best practices
Docker’s products help you adopt these best practices — we are focused on enhancing the software development lifecycle, especially around refining the inner loop. Products like Docker Desktop allow your dev team in the inner loop to run, test, code, and build everything fast and consistently. This consistency eliminates the “it works on my machine” issue, meaning applications behave the same in both development and production.
Shifting left lets your dev team identify problems earlier in your software project lifecycle. When you detect issues sooner, you increase efficiency and help ensure secure builds and compliance. By shifting security left with Docker Scout, your dev teams can identify vulnerabilities sooner and help avoid issues down the road.
Another example of shifting left involves testing — doing testing earlier in the process leads to more robust software and faster release cycles. This is when Testcontainers Cloud comes in handy because it enables developers to run reliable integration tests, with real dependencies defined in code.
Accelerate development within the hybrid inner loop
We see more and more companies adopting the so-called hybrid inner loop, which combines the best of two worlds — local and cloud. The results provide greater flexibility for your dev teams and encourage better collaboration. For example, Docker Build Cloud uses the power of the cloud to speed up build time without sacrificing the local development experience that developers love.
By using these Docker products across the software development life cycle, teams get quick feedback loops and faster issue resolution, ensuring a smooth development flow from inception to deployment.
Simplifying AI application development
When you’re using the right tools and processes to accelerate your application delivery and maximize efficiency throughout your SDLC, processes that were once cumbersome become your new baseline, freeing up time for true innovation.
Docker also helps accelerate innovation by simplifying AI/ML development. We are continually investing in AI to help your developers deliver AI-backed applications that differentiate your business and enhance competitiveness.
Docker AI tools
Docker’s GenAI Stack accelerates the incorporation of large language models (LLMs) and AI/ML into your code, enabling the delivery of AI-backed applications. All containers work harmoniously and are managed directly from Docker Desktop, allowing your team to monitor and adjust components without leaving their development environment. Deploying the GenAI Stack is quick and easy, and leveraging Docker’s containerization technology helps speed setup and simplify scaling as applications grow.
Earlier this year, we announced the preview of Docker Extension for GitHub Copilot. By standardizing best practices and enabling integrations with tools like GitHub Copilot, Docker empowers developers to focus on innovation, closing the gap from the first line of code to production.
And, more recently, we launched the Docker AI Catalog in Docker Hub. This new feature simplifies the process of integrating AI into applications by providing trusted and ready-to-use content supported by comprehensive documentation. Your dev team will benefit from shorter development cycles, improved productivity, and a more streamlined path to integrating AI into both new and existing applications.
Wrapping up
Docker products help you establish sound processes and practices related to shifting left and discovering issues earlier to avoid headaches down the road. This approach ultimately unlocks developer productivity, giving your dev team more time to code and innovate. Docker also allows you to quickly use AI to close knowledge gaps and offers trusted tools to build AI/ML applications and accelerate time to market.
To see how Docker continues to empower developers with the latest innovations and tools, check out our Docker 2024 Highlights.
Learn about Docker’s updated subscriptions and find the ideal plan for your team’s needs.
Kubernetes is an open source platform for automating the deployment, scaling, and management of containerized applications across clusters of machines. It’s become the go-to solution for orchestrating containers in production environments. But if you’re developing or testing locally, setting up a full Kubernetes cluster can be complex. That’s where Docker Desktop comes in — it lets you run Kubernetes directly on your local machine, making it easy to test microservices, CI/CD pipelines, and containerized apps without needing a remote cluster.
Getting Kubernetes up and running can feel like a daunting task, especially for developers working in local environments. But with Docker Desktop, spinning up a fully functional Kubernetes cluster is simpler than ever. Whether you’re new to Kubernetes or just want an easy way to test containerized applications locally, Docker Desktop provides a streamlined solution. In this guide, we’ll walk through the steps to start a Kubernetes cluster on Docker Desktop and offer troubleshooting tips to ensure a smooth experience.
Note: Docker Desktop’s Kubernetes cluster is designed specially for local development and testing; it is not for production use.
Benefits of running Kubernetes in Docker Desktop
The benefits of this setup include:
Easy local Kubernetes cluster: A fully functional Kubernetes cluster runs on your local machine with minimal setup, handling network access between the host and Kubernetes as well as storage management.
Easier learning path and developer convenience: For developers familiar with Docker but new to Kubernetes, having Kubernetes built into Docker Desktop offers a low-friction learning path.
Testing Kubernetes-based applications locally: Docker Desktop gives developers a local environment to test Kubernetes-based microservices applications that require Kubernetes features like services, pods, ConfigMaps, and secrets without needing access to a remote cluster. It also helps developers to test CI/CD pipelines locally.
How to start Kubernetes cluster on Docker Desktop in three steps
Install Docker Desktop on the operating system of your choice. Currently, the supported operating systems are macOS, Linux, and Windows.
In the Settings menu, select Kubernetes > Enable Kubernetes and then Apply & restart to start a one-node Kubernetes cluster (Figure 1). Typically, the time it takes to set up the Kubernetes cluster depends on your internet speed to pull the needed images.
Figure 1: Starting Kubernetes.
Once the Kubernetes cluster is started successfully, you can see the status from the Docker Desktop dashboard or the command line.
From the dashboard (Figure 2):
Figure 2: Status from the dashboard.
The command-line status:
$ kubectl get node
NAME STATUS ROLES AGE VERSION
docker-desktop Ready control-plane 5d v1.30.2
Getting Kubernetes support
Docker bundles Kubernetes but does not provide official Kubernetes support. If you are experiencing issues with Kubernetes, however, you can get support in several ways, including from the Docker community, Docker guides, and GitHub documentation:
The command will show you where the diagnostics file is saved:
Gathering diagnostics for ID into /var/folders/50/<Random Character>/<Random Character>/<Machine unique ID>/<YYYYMMDDTTTT>.zip.
In this case, the file is saved at /var/folders/50/<Random Characters>/<Random Characters>/<YYYMMDDTTTT>.zip. Unzip the file (<YYYYMMDDTTTT>.zip) where you can find the logs file for Docker Desktop.
Check for logs
Checking for logs instead of guessing the issue is good practice. Understanding what Kubernetes components are available and what their functions are is essential before you start troubleshooting. You can narrow down the process by looking at the specific component logs. Look for the keyword error or fatal in the logs.
Depending on which platform you are using, one method is to use the grep command and search for the keyword in the macOS terminal, a Linux distro for WSL2, or the Linux terminal for the file you unzipped:
$ grep -Hrni "<keyword>" <The path of the unzipped file>
## For example, one of the error found related to Kubernetes in the "com.docker.backend.exe" logs:
$ grep -Hrni "error" *
[com.docker.backend.exe.log:[2022-12-05T05:24:39.377530700Z][com.docker.backend.exe][W] starting kubernetes: 1 error occurred:
com.docker.backend.exe.log: * starting kubernetes: pulling kubernetes images: pulling registry.k8s.io/coredns:v1.9.3: Error response from daemon: received unexpected HTTP status: 500 Internal Server Error
Troubleshooting example
Let’s say you notice there is an issue starting up the cluster. This issue could be related to the Kubelet process, which works as a node-level agent to help with container management and orchestration within a Kubernetes cluster. So, you should check the Kubelet logs.
But, where is the Kubelet log located? It’s at log/vm/kubelet.log in the diagnostics file.
An example of a possible related issue can be found in the kubelet.log. The images needed to set up Kubernetes are not able to be pulled due to network/internet restrictions. You might find errors related to failing to pull the necessary Kubernetes images to set up the Kubernetes cluster.
For example:
starting kubernetes: pulling kubernetes images: pulling registry.k8s.io/coredns:v1.9.3: Error response from daemon: received unexpected HTTP status: 500 Internal Server Error
Normally, 10 images are needed to set up the cluster. The following output is from a macOS running Docker Desktop version 4.33:
$ docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
docker/desktop-kubernetes kubernetes-v1.30.2-cni-v1.4.0-critools-v1.29.0-cri-dockerd-v0.3.11-1-debian 5ef3082e902d 4 weeks ago 419MB
registry.k8s.io/kube-apiserver v1.30.2 84c601f3f72c 7 weeks ago 112MB
registry.k8s.io/kube-scheduler v1.30.2 c7dd04b1bafe 7 weeks ago 60.5MB
registry.k8s.io/kube-controller-manager v1.30.2 e1dcc3400d3e 7 weeks ago 107MB
registry.k8s.io/kube-proxy v1.30.2 66dbb96a9149 7 weeks ago 87.9MB
registry.k8s.io/etcd 3.5.12-0 014faa467e29 6 months ago 139MB
registry.k8s.io/coredns/coredns v1.11.1 2437cf762177 11 months ago 57.4MB
docker/desktop-vpnkit-controller dc331cb22850be0cdd97c84a9cfecaf44a1afb6e 3750dfec169f 14 months ago 35MB
registry.k8s.io/pause 3.9 829e9de338bd 22 months ago 514kB
docker/desktop-storage-provisioner v2.0 c027a58fa0bb 3 years ago 39.8MB
You can check whether you successfully pulled the 10 images by running docker image ls. If images are missing, a workaround is to save the missing image using docker image save from a machine that successfully starts the Kubernetes cluster (provided both run the same Docker Desktop version). Then, you can transfer the image to your machine, use docker image load to load the image into your machine, and tag it.
For example, if the registry.k8s.io/coredns:v<VERSION> image is not available, you can follow these steps:
Use docker image save from a machine that successfully starts the Kubernetes cluster to save it as a tar file: docker save registry.k8s.io/coredns:v<VERSION> > <Name of the file>.tar.
Manually transfer the <Name of the file>.tar to your machine.
Use docker image load to load the image on your machine: docker image load <<Name of the file>.tar.
Tag the image: docker image tag registry.k8s.io/coredns:v<VERSION> <Name of the file>.tar.
Re-enable the Kubernetes from your Docker Desktop’s settings.
Check other logs in the diagnostics log.
What to look for in the diagnostics log
In the diagnostics log, look for the folder starting named kube/. (Note that the <kube> below, for macOS and Linux is kubectl and for Windows is kubectl.exe.)
kube/get-namespaces.txt: List down all the namespaces, equal to <kube> --context docker-desktop get namespaces.
kube/describe-nodes.txt: Describe the docker-desktop node, equal to <kube> --context docker-desktop describe nodes.
kube/describe-pods.txt: Description of all pods running in the Kubernetes cluster.
kube/describe-services.txt: Description of the services running, equal to <kube> --context docker-desktop describe services --all-namespaces.
You also can find other useful Kubernetes logs in the mentioned folder.
Search for known issues
For any error message found in the steps above, you can search for known Kubernetes issues on GitHub to see if a workaround or any future permanent fix is planned.
Reset or reboot
If the previous steps weren’t helpful, try a reboot. And, if the previous steps weren’t helpful, try a reboot. And, if a reboot is not helpful, the last alternative is to reset your Kubernetes cluster, which often helps resolve issues:
Reboot: To reboot, restart your machine. Rebooting a machine in a Kubernetes cluster can help resolve issues by clearing transient states and restoring the system to a clean state.
Reset: For a reset, navigate to Settings > Kubernetes > Reset the Kubernetes Cluster. Resetting a Kubernetes cluster can help resolve issues by essentially reverting the cluster to a clean state, and clearing out misconfigurations, corrupted data, or stuck resources that may be causing problems.
Bringing Kubernetes to your local development environment
This guide offers a straightforward way to start a Kubernetes cluster on Docker Desktop, making it easier for developers to test Kubernetes-based applications locally. It covers key benefits like simple setup, a more accessible learning path for beginners, and the ability to run tests without relying on a remote cluster. We also provide some troubleshooting tips and resources for resolving common issues.
Whether you’re just getting started or looking to improve your local Kubernetes workflow, give it a try and see what you can achieve with Docker Desktop’s Kubernetes integration.
In modern software development, businesses are searching for smarter ways to streamline workflows and deliver value faster. For developers, this means tackling challenges like collaboration and security head-on, while driving efficiency that contributes directly to business performance. But how do you address potential roadblocks before they become costly issues in production? The answer lies in optimizing the development inner loop — a core focus for the future of app development.
By identifying and resolving inefficiencies early in the development lifecycle, software development teams can overcome common engineering challenges such as slow dev cycles, spiraling infrastructure costs, and scaling challenges. With Docker’s integrated suite of development tools, developers can achieve new levels of engineering efficiency, creating high-quality software while delivering real business impact.
Let’s explore how Docker is transforming the development process, reducing operational overhead, and empowering teams to innovate faster.
Speed up software development lifecycles: Faster gains with less effort
A fast software development lifecycle is a crucial aspect for delivering value to users, maintaining a competitive edge, and staying ahead of industry trends. To enable this, software developers need workflows that minimize friction and allow them to iterate quickly without sacrificing quality. That’s where Docker makes a difference. By streamlining workflows, eliminating bottlenecks, and automating repetitive tasks, Docker empowers developers to focus on high-impact work that drives results.
Consistency across development environments is critical for improving speed. That’s why Docker helps developers create consistent environments across local, test, and production systems. In fact, a recent study reported developers experiencing a 6% increase in productivity when leveraging Docker Business. This consistency eliminates guesswork, ensuring developers can concentrate on writing code and improving features rather than troubleshooting issues. With Docker, applications behave predictably across every stage of the development lifecycle.
Docker also accelerates development by significantly reducing time spent on iteration and setup. More specifically, organizations leveraging Docker Business achieved a three-month faster time-to-market for revenue-generating applications. Engineering teams can move swiftly through development stages, delivering new features and bug fixes faster. By improving efficiency and adapting to evolving needs, Docker enables development teams to stay agile and respond effectively to business priorities.
Improve scaling agility: Flexibility for every scenario
Scalability is another essential for businesses to meet fluctuating demands and seize opportunities. Whether handling a surge in user traffic or optimizing resources during quieter periods, the ability to scale applications and infrastructure efficiently is a critical advantage. Docker makes this possible by enabling teams to adapt with speed and flexibility.
Docker’s cloud-native approach allows software engineering teams to scale up or down with ease to meet changing requirements. This flexibility supports experimentation with cutting-edge technologies like AI, machine learning, and microservices without disrupting existing workflows. With this added agility, developers can explore new possibilities while maintaining focus on delivering value.
Whether responding to market changes or exploring the potential of emerging tools, Docker equips companies to stay agile and keep evolving, ensuring their development processes are always ready to meet the moment.
Optimize resource efficiency: Get the most out of what you’ve got
Maximizing resource efficiency is crucial for reducing costs and maintaining agility. By making the most of existing infrastructure, businesses can avoid unnecessary expenses and minimize cloud scaling costs, meaning more resources for innovation and growth. Docker empowers teams to achieve this level of efficiency through its lightweight, containerized approach.
Docker containers are designed to be resource-efficient, enabling multiple applications to run in isolated environments on the same system. Unlike traditional virtual machines, containers minimize overhead while maintaining performance, consolidating workloads, and lowering the operational costs of maintaining separate environments. For example, a leading beauty company reduced infrastructure costs by 25% using Docker’s enhanced CPU and memory efficiency. This streamlined approach ensures businesses can scale intelligently while keeping infrastructure lean and effective.
By containerizing applications, businesses can optimize their infrastructure, avoiding costly upgrades while getting more value from their current systems. It’s a smarter, more efficient way to ensure your resources are working at their peak, leaving no capacity underutilized.
Establish cost-effective scaling: Growth without growing pains
Similarly, scaling efficiently is essential for businesses to keep up with growing demands, introduce new features, or adopt emerging technologies. However, traditional scaling methods often come with high upfront costs and complex infrastructure changes. Docker offers a smarter alternative, enabling development teams to scale environments quickly and cost-effectively.
With a containerized model, infrastructure can be dynamically adjusted to match changing needs. Containers are lightweight and portable, making it easy to scale up for spikes in demand or add new capabilities without overhauling existing systems. This flexibility reduces financial strain, allowing businesses to grow sustainably while maximizing the use of cloud resources.
Docker ensures that scaling is responsive and budget-friendly, empowering teams to focus on innovation and delivery rather than infrastructure costs. It’s a practical solution to achieve growth without unnecessary complexity or expense.
Software engineering efficiency at your fingertips
The developer community consistently ranks Docker highly, including choosing it as the most-used and most-admired developer tool in Stack Overflow’s Developer Survey. With Docker’s suite of products, teams can reach a new level of efficient software development by streamlining the dev lifecycle, optimizing resources, and providing agile, cost-effective scaling solutions. By simplifying complex processes in the development inner loop, Docker enables businesses to deliver high-quality software faster while keeping operational costs in check. This allows developers to focus on what they do best: building innovative, impactful applications.
By removing complexity, accelerating development cycles, and maximizing resource usage, Docker helps businesses stay competitive and efficient. And ultimately, their teams can achieve more in less time — meeting market demands with efficiency and quality.
Ready to supercharge your development team’s performance? Download our white paper to see how Docker can help streamline your workflow, improve productivity, and deliver software that stands out in the market.
“You don’t want to think about security — until you have to.”
That’s what I’d tell you if I were being honest about the state of development at most organizations I have spoken to. Every business out there is chasing one thing: speed. Move faster. Innovate faster. Ship faster. To them, speed is survival. There’s something these companies are not seeing — a shadow. An unseen risk hiding behind every shortcut, every unchecked tool, and every corner cut in the name of “progress.”
Businesses are caught in a relentless sprint, chasing speed and progress at all costs. However, as Cal Newport reminds us in Slow Productivity, the race to do more — faster — often leads to chaos, inefficiency, and burnout. Newport’s philosophy calls for deliberate, focused work on fewer tasks with greater impact. This philosophy isn’t just about how individuals work — it’s about how businesses innovate. Development teams rushing to ship software often cut corners, creating vulnerabilities that ripple through the entire supply chain.
The strategic risk: An unsecured development pipeline
Development environments are the foundation of your business. You may think they’re inherently secure because they’re internal. Foundations crumble when you don’t take care of them, and that crack doesn’t just swallow your software — it swallows established customer trust and reputation. That’s how it starts: a rogue tool here, an unpatched dependency there, a developer bypassing IT to do things “their way.” They’re not trying to ruin your business. They’re trying to get their jobs done. But sometimes you can’t stop a fire after it’s started. Shadow IT isn’t just inconvenient — it’s dangerous. It’s invisible, unmonitored, and unregulated. It’s the guy leaving the back door open in a neighborhood full of burglars.
You need control, isolation, and automation — not because they’re nice to have, but because you’re standing on a fault line without them. Docker gives you that control. Fine-grained, role-based access ensures that the only people touching your most critical resources are the ones you trust. Isolation through containerization keeps every piece of your pipeline sealed tight so vulnerabilities don’t spread. Automation takes care of the updates, the patch management, and the vulnerabilities before they become a problem. In other words, you don’t have to hope your foundation is solid — you’ll know it is.
Shadow IT: A growing concern
While securing official development environments is critical, shadow IT remains an insidious and hidden threat. Shadow IT refers to tools, systems, or environments implemented without explicit IT approval or oversight. In the pursuit of speed, developers may bypass formal processes to adopt tools they find convenient. However, this creates unseen vulnerabilities with far-reaching consequences.
In the pursuit of performative busywork, developers often take shortcuts, grabbing tools and spinning up environments outside the watchful eyes of IT. The intent may not be malicious; it’s just human nature. Here’s the catch: What you don’t see, you can’t protect. Shadow IT is like a crack in the dam: silent, invisible, and spreading. It lets unvetted tools and insecure code slip into your supply chain, infecting everything from development to production. Before you know it, that “quick fix” has turned into a legal nightmare, a compliance disaster, and a stain on your reputation. In industries like finance or healthcare, that stain doesn’t wash out quickly.
A solution rooted in integration
The solution lies in a unified, secure approach to development environments that removes the need for shadow IT while fortifying the software supply chain. Docker addresses these vulnerabilities by embedding security directly into the development lifecycle. Our solution is built on three foundational principles: control, isolation, and automation.
Control through role-based access management: Docker Hub establishes clear boundaries within development environments by enabling fine-grained, role-based access. You want to ensure that only authorized personnel can interact with sensitive resources, which will ideally minimize the risk of unintended or malicious actions. Docker also enables publishers to enforce role-based access controls, ensuring only authorized users can interact with development resources. It streamlines patch management through verified, up-to-date images. Docker Official Images and Docker Verified Publisher content are scanned with our in-house image analysis tool, Docker Scout. This helps find vulnerabilities before they can be exploited.
Isolation through containerization: Docker’s value proposition centers on its containerization technology. By creating isolated development spaces, Docker prevents cross-environment contamination and ensures that applications and their dependencies remain secure throughout the development lifecycle.
Automation for seamless security:Recognizing the need for speed in modern development cycles, Docker integrates recommendations with Scout through recommendations for software updates and patch management for CVEs. This ensures that environments remain secure against emerging threats without interrupting the flow of innovation.
Delivering tangible business outcomes
Businesses are always going to face this tension between speed and security, but the truth is you don’t have to choose. Docker gives you both. It’s not just a platform; it’s peace of mind. Because when your foundation is solid, you stop worrying about what could go wrong. You focus on what comes next.
Consider the example of a development team working on a high-stakes application feature. Without secure environments, a single oversight — such as an unregulated access point — can result in vulnerabilities that disrupt production and erode customer trust. By leveraging Docker’s integrated security solutions, the team mitigates these risks, enabling them to focus on value creation rather than crisis management.
Aligning innovation with security
As a previous post covers, securing the development pipeline is not simply deploying technical solutions but establishing trust across the entire software supply chain. With Docker Content Trust and image signing, organizations can ensure the integrity of software components at every stage, reducing the risk of third-party code introducing unseen vulnerabilities. By eliminating the chaos of shadow IT and creating a transparent, secure development process, businesses can mitigate risk without slowing the pace of innovation.
The tension between speed and security has long been a barrier to progress, but businesses can confidently pursue both with Docker. A secure development environment doesn’t just protect against breaches — it strengthens operational resilience, ensures regulatory compliance, and safeguards brand reputation. Docker empowers organizations to innovate on a solid foundation as unseen risks lurk within an organization’s fragmented tools and processes.
Security isn’t a luxury. It’s the cost of doing business. If you care about growth, if you care about trust, if you care about what your brand stands for, then securing your development environments isn’t optional — it’s survival. Docker Business doesn’t just protect your pipeline; it turns it into a strategic advantage that lets you innovate boldly while keeping your foundation unshakable. Integrity isn’t something you hope for — it’s something you build.
Start today
Securing your software supply chain is a critical step in building resilience and driving sustained innovation. Docker offers the tools to create fortified development environments where your teams can operate at their best.
The question is not whether to secure your development pipeline — it’s how soon you can start. Explore Docker Hub and Scout today to transform your approach to innovation and security. In doing so, you position your organization to navigate the complexities of the modern development landscape with confidence and agility.
Season’s greetings! I set this up to auto-publish while I’m off sipping breakfast champagne, so don’t yell at me in the comments — I’m not really here.
I hope you’re having the best day, and if you unwrapped something made by Raspberry Pi for Christmas, I hope the following helps you navigate the first few hours with your shiny new device.
Power and peripherals
If you’ve received, say, a Raspberry Pi 5 or 500 on its own and have no idea what you need to plug it in, the product pages on raspberrypi.com often feature sensible suggestions for additional items you might need.
Scroll to the bottom of the Raspberry Pi 5 product page, for example, and you’ll find a whole ‘Accessories’ section featuring affordable things specially designed to help you get the best possible performance from your computer.
You can find all our hardware here, so have a scroll to find your particular Christmas gift.
Dedicated documentation
There are full instructions on how everything works if you know where to look. Our fancy documentation site holds the keys to all of your computing dreams.
Your one-stop shop for all your Raspberry Pi questions
If all the suggestions above aren’t working out for you, there are approx. one bajillion experts eagerly awaiting your questions on the Raspberry Pi forums. Honestly, I’ve barely ever seen a question go unanswered. You can throw the most esoteric, convoluted problem out there and someone will have experienced the same issue and be able to help. Lots of our engineers hang out in the forums too, so you may even get an answer direct from Pi Towers.
Be social
Outside of our official forums, you’ve all cultivated an excellent microcosm of Raspberry Pi goodwill on social media. Why not throw out a question or a call for project inspiration on our official Facebook, Threads, Instagram, TikTok, or “Twitter” account? There’s every chance someone who knows what they’re talking about will give you a hand.
Also, tag us in photos of your festive Raspberry Pi gifts! I will definitely log on to see and share those.
Again, we’re not really here, it’s Christmas!
I’m off again now to catch the new Wallace and Gromit that’s dropping on Christmas Day (BIG news here in the UK), but we’ll be back in early January to hang out with you all in the blog comments and on social.
Glad tidings, joy, and efficient digestion wished on you all.
Collaboration and security are essential for delivering high-quality applications in modern software development, especially in cloud-native environments. Developers navigate intricate workflows, connect diverse systems, and safeguard applications against emerging threats — all while maintaining velocity and efficiency.
Think of development as preparing a multi-course meal in a high-pressure, professional kitchen, where precision, timing, and communication are critical. Each developer is a chef working on different parts of the dish, passing ingredients (code) along the way. When one part of the system encounters delays, it can ripple across the process, impacting the final result. Similarly, poor collaboration or security gaps can derail a project, causing delays and inefficiencies.
Docker serves as the kitchen manager, ensuring everything flows smoothly, ingredients are passed securely, and security is integrated from start to finish.
Seamless collaboration with Docker Hub and Testcontainers Cloud
Success in a professional kitchen depends on clear communication and coordination. In development, it’s no different. Docker’s collaboration tools, like Docker Hub and Testcontainers Cloud, simplify how teams work together, share resources, and test efficiently.
Docker Hub can be thought of as a kitchen’s “prepped ingredients station.” It’s where some of the most essential ingredients are always ready to go. With a vast selection of curated, trusted images, developers can quickly access high-quality, pre-configured containers, ensuring consistency and reducing the chance for mistakes.
Testcontainers Cloud is like the kitchen’s test station, providing on-demand, production-like environments for testing. Developers can spin up these environments quickly, reducing setup time and ensuring code performs in a real-world setting.
Effective coordination is critical whether you’re in a kitchen or on a development team, especially when projects involve distributed or hybrid teams. Clear communication ensures everyone is aligned and productive. The Docker suite of products provides the tools that make it possible for companies to more easily break down silos, share resources seamlessly, and ensure alignment — no matter how large your team is or where they work!
By streamlining collaboration, Docker reduces complexity and allows teams to move forward with confidence. With Docker Hub, Testcontainers Cloud, and integrated security features, teams can share resources, track progress, and catch issues early, enabling them to deliver high-quality results on time.
These tools improve efficiency, reduce errors, and help teams move faster through the development inner loop by making collaboration seamless and resource sharing simple.
Integrated security from code to production
Embedding security into every development step is essential to maintaining speed and delivering high-quality software. With Docker, security is embedded into every step of the development process so teams can identify and fix issues earlier than ever.
Docker Scout monitors container images in real-time, identifying vulnerabilities early to ensure your software is production-ready. By identifying and resolving risks early, developers can maintain high-quality standards and accelerate time to market.
Docker also integrates additional security features that work behind the scenes:
Hardened Docker Desktop (HDD) strengthens container isolation, protecting against software supply chain risks like malware.
Trusted Content offers developers secure, reliable base images, reducing vulnerabilities in the app’s foundation.
By building security into the workflow, Docker helps teams identify risks earlier, improve code quality, and maintain momentum without compromising safety.
Efficiency in action with Docker
Speed, collaboration, and security are paramount in today’s development landscape. Docker simplifies and secures the development process, helping teams collaborate efficiently and deliver secure, high-quality software faster.
Just as a well-managed kitchen runs smoothly, Docker helps development teams stay coordinated, ensuring security and productivity work together in perfect harmony. Docker removes complexity, accelerates delivery, and embeds security, enabling teams to create efficient, secure applications on time.
Ready to boost efficiency and collaboration in your development process? Explore the Docker suite of productsto see how they can streamline your workflow and improve your team’s productivity today.
Containerized application development has revolutionized modern software delivery, but slow image builds in CI/CD pipelines can bring developer productivity to a halt. Even with AWS CodeBuild automating application testing and building, teams face challenges like resource constraints, inefficient caching, and complex multi-architecture builds that lead to delays, lower release frequency, and prolonged recovery times.
Enter Docker Build Cloud, a high-performance cloud service designed to streamline image builds, integrate seamlessly with AWS CodeBuild, and reduce build times dramatically. With Docker Build Cloud, you gain powerful cloud-based builders, shared caching, and native multi-architecture support — all while keeping your CI/CD pipelines efficient and your developers focused on delivering value faster.
In this post, we’ll explore how AWS CodeBuild combined with Docker Build Cloud tackles common bottlenecks, boosts build performance, and simplifies workflows, enabling teams to ship more quickly and reliably.
By using AWS CodeBuild, you can automate the build and testing of container applications, enabling the construction of efficient CI/CD workflows. AWS CodeBuild is also integrated with AWS Identity and Access Management (IAM), allowing detailed configuration of access permissions for build processes and control over AWS resources.
Container images built with AWS CodeBuild can be stored in Amazon Elastic Container Registry (Amazon ECR) and deployed to various AWS services, such as Amazon Elastic Container Service (Amazon ECS), Amazon Elastic Kubernetes Service (Amazon EKS), AWS Fargate, or AWS Lambda (Figure 1). Additionally, these services can leverage AWS Graviton, which adopts Arm-based architectures, to improve price performance for compute workloads.
Figure 1: CI/CD pipeline for AWS ECS using AWS CodeBuild (ECS Workshop).
Challenges of container image builds with AWS CodeBuild
Regardless of the tool used, building container images in a CI pipeline often takes a significant amount of time. This can lead to the following issues:
Reduced development productivity
Lower release frequency
Longer recovery time in case of failures
The main reasons why build times can be extended include:
1. Machines for building
Building container images requires substantial resources (CPU, RAM). If the machine specifications used in the CI pipeline are inadequate, build times can increase.
For simple container image builds, the impact may be minimal, but in cases of multi-stage builds or builds with many dependencies, the effect can be significant.
AWS CodeBuild allows changing instance types to improve these situations. However, such changes can apply to parts of the pipeline beyond container image builds, and they also increase costs.
Developers need to balance cost and build speed to optimize the pipeline.
2. Container image cache
In local development environments, Docker’s build cache can shorten rebuild times significantly by reusing previously built layers, avoiding redundant processing for unchanged parts of the Dockerfile. However, in cloud-based CI services, clean environments are used by default, so cache cannot be utilized, resulting in longer build times.
Although there are ways to use storage or container registries to leverage caching, these often are not employed because they introduce complexity in configuration and overhead from uploading and downloading cache data.
3. Multi-architecture builds (AMD64, Arm64)
To use Arm-based architectures like AWS Graviton in Amazon EKS or Amazon ECS, Arm64-compatible container image builds are required.
With changes in local environments, such as Apple Silicon, cases requiring multi-architecture support for AMD64 and Arm64 have increased. However, building images for different architectures (for example, building x86 on Arm, or vice versa) often requires emulation, which can further increase build times (Figure 2).
Although AWS CodeBuild provides both AMD64 and Arm64 instances, running them as separate pipelines is necessary, leading to more complex configurations and operations.
Figure 2: Creating multi-architecture Docker images using AWS CodeBuild.
Accelerating container image builds with Docker Build Cloud
The Docker Build Cloud service executes the Docker image build process in the cloud, significantly reducing build time and improving developer productivity (Figure 3).
Figure 3: How Docker Build Cloud works.
Particularly in CI pipelines, Docker Build Cloud enables faster container image builds without the need for significant changes or migrations to existing pipelines.
Docker Build Cloud includes the following features:
High-performance cloud builders: Cloud builders equipped with 16 vCPUs and 32GB RAM are available. This allows for faster builds compared to local environments or resource-constrained CI services.
Shared cache utilization: Cloud builders come with 200 GiB of shared cache, significantly reducing build times for subsequent builds. This cache is available without additional configuration, and Docker Build Cloud handles the cache maintenance for you.
Multi-architecture support (AMD64, Arm64): Docker Build Cloud supports native builds for multi-architecture with a single command. By specifying --platform linux/amd64,linux/arm64 in the docker buildx build command or using Bake, images for both Arm64 and AMD64 can be built simultaneously. This approach eliminates the need to split the pipeline for different architectures.
Architecture of AWS CodeBuild + Docker Build Cloud
Figure 4 shows an example of how to use Docker Build Cloud to accelerate container image builds in AWS CodeBuild:
Once the builder is successfully created, a guide is displayed for using it in local environments (Docker Desktop, CLI) or CI/CD environments (Figure 5).
Figure 5: Setup instructions of Docker Build Cloud.
Additionally, to use Docker Build Cloud from AWS CodeBuild, a Docker personal access token (PAT) is required. Store this token in AWS Secrets Manager for secure access.
Setting up the AWS CodeBuild pipeline
Next, set up the AWS CodeBuild pipeline. You should prepare an Amazon ECR repository to store the container images beforehand.
The following settings are used to create the AWS CodeBuild pipeline:
AMD64 instance with 3GB memory and 2 vCPUs.
Service role with permissions to push to Amazon ECR and access the Docker personal access token from AWS Secrets Manager.
In the install phase, Buildx, which is necessary for using Docker Build Cloud, is installed.
Although Buildx may already be installed in AWS CodeBuild, it might be an unsupported version for Docker Build Cloud. Therefore, it is recommended to install the latest version.
In the pre_build phase, the following steps are performed:
Log in to Amazon ECR.
Log in to Docker (Build Cloud).
Specify the cloud builder.
In the build phase, the image tag is specified, and the container image is built and pushed to Amazon ECR.
Instead of separating the build and push commands, using --push to directly push the image to Amazon ECR helps avoid unnecessary file transfers, contributing to faster builds.
Results comparison
To make a comparison, an AWS CodeBuild pipeline without Docker Build Cloud is created. The same instance type (AMD64, 3GB memory, 2vCPU) is used, and the build is limited to AMD64 container images.
Additionally, Docker login is used to avoid the pull rate limit imposed by Docker Hub.
Figure 6: The result of the execution without Docker Build Cloud.
Figure 7 shows the execution result of the AWS CodeBuild pipeline using Docker Build Cloud:
Figure 7: The result of the execution with Docker Build Cloud.
The results may vary depending on the container images being built and the state of the cache, but it was possible to build container images much faster and achieve multi-architecture builds (AMD64 and Arm64) within a single pipeline.
Conclusion
Integrating Docker Build Cloud into a CI/CD pipeline using AWS CodeBuild can dramatically reduce build times and improve release frequency. This allows developers to maximize productivity while delivering value to users more quickly.
As mentioned previously, the new Docker subscription already includes a free tier for Docker Build Cloud. Take advantage of this opportunity to test how much faster you can build container images for your current projects.
In 2024, as developers and engineering teams focused on delivering high-quality, secure software faster, Docker continued to evolve with impactful updates and a streamlined user experience. This commitment to empowering developers was recognized in the annual Stack Overflow Developer Survey, where Docker ranked as one of the most loved and widely used tools for yet another year. Here’s a look back at Docker’s 2024 milestones and how we helped teams build, test, and deploy with greater ease, security, and control than ever.
Streamlining the developer experience
Docker focused heavily on streamlining workflows, creating efficiencies, and reducing the complexities often associated with managing multiple tools. One big announcement in 2024 is our upgraded Docker plans. With the launch of updated Docker subscriptions, developers now have access to the entire suite of Docker products under their existing subscription.
The all-in-one subscription model enables seamless integration of Docker Desktop, Docker Hub, Docker Build Cloud, Docker Scout, and Testcontainers Cloud, giving developers everything they need to build efficiently. By providing easy access to the suite of products and flexibility to scale, Docker allows developers to focus on what matters most — building and innovating without unnecessary distractions.
For more details on Docker’s all-in-one subscription approach, check out our Docker plans announcement.
Build up to 39x faster with Docker Build Cloud
Docker Build Cloud, introduced in 2024, brings the best of two worlds — local development and the cloud to developers and engineering teams worldwide. It offloads resource-intensive build processes to the cloud, ensuring faster, more consistent builds while freeing up local machines for other tasks.
A standout feature is shared build caches, which dramatically improve efficiency for engineering teams working on large-scale projects. Shared caches allow teams to avoid redundant rebuilds by reusing intermediate layers of images across builds, accelerating iteration cycles and reducing resource consumption. This approach is especially valuable for collaborative teams working on shared codebases, as it minimizes duplicated effort and enhances productivity.
Docker Build Cloud also offers native support for multi-architecture builds, eliminating the need for setting up and maintaining multiple native builders. This support removes the challenges associated with emulation, further improving build efficiency.
We’ve designed Docker Build Cloud to be easy to set up wherever you run your builds, without requiring a massive lift-and-shift effort. Docker Build Cloud also works well with Docker Compose, GitHub Actions, and other CI solutions. This means you can seamlessly incorporate Docker Build Cloud into your existing development tools and services and immediately start reaping the benefits of enhanced speed and efficiency.
Optimizing development workflows with performance enhancements
In 2024, Docker Desktop introduced a series of enterprise-grade performance enhancements designed to streamline development workflows at scale. These updates cater to the unique needs of development teams operating in diverse, high-performance environments.
One notable feature is the Virtual Machine Manager (VMM) in Docker Desktop for Mac, which provides a robust alternative to the Apple Virtualization Framework. Available since Docker Desktop 4.35, VMM significantly boosts performance for native Arm-based images, delivering faster and more efficient workflows for M1 and M2 Mac users. For development teams relying on Apple’s latest hardware, this enhancement translates into reduced build times and a smoother experience when working with containerized applications.
Additionally, Docker Desktop expanded its platform support to include Red Hat Enterprise Linux (RHEL) and Windows on Arm architectures, enabling organizations to maintain a consistent Docker Desktop experience across a wide array of operating systems. This flexibility ensures that development teams can optimize their workflows regardless of the underlying platform, leveraging platform-specific optimizations while maintaining uniformity in their tooling.
These advancements reflect Docker’s unwavering commitment to speed, reliability, and cross-platform support, ensuring that development teams can scale their operations without bottlenecks. By minimizing downtime and enhancing performance, Docker Desktop empowers developers to focus on innovation, improving productivity across even the most demanding enterprise environments.
More options to improve file operations for large projects
We enhanced Docker Desktop with synchronized file shares (Figure 1), a feature that can significantly improve file operation speeds by 2-10x. This enhancement brings fast and flexible host-to-VM file sharing, offering a performance boost for developers dealing with extensive codebases.
Synchronized file sharing is ideal for developers who:
Develop on projects that consist of a significant number of files (such as PHP or Node projects).
Develop using large repositories or monorepos with more than 100,000 files, totaling significant storage.
Utilize virtual file systems (such as VirtioFS, gRPC FUSE, or osxfs) and face scalability issues with their workflows.
Encounter performance limitations and want a seamless file-sharing solution without worrying about ownership conflicts.
This integration streamlines workflows, allowing developers to focus more on coding and less on managing file synchronization issues and slow file read times.
Figure 1: Synchronized file shares.
Enhancing developer productivity with Docker Debug
Docker Debug enhances the ability of developer teams to debug any container, especially those without a shell (that is, distroless or scratch images). The ability to peek into “secure” images significantly improves the debugging experience for both local and remote containerized applications.
Docker Debug does this by attaching a dedicated debugging toolkit to any image and allows developers to easily install additional tools for quick issue identification and resolution. Docker Debug not only streamlines debugging for both running and stopped containers but also is accessible directly from both the Docker Desktop CLI and GUI (Figure 2).
Figure 2: Docker Debug.
Being able to troubleshoot images without modifying them is crucial for maintaining the security and performance of containerized applications, especially those images that traditionally have been hard to debug. Docker Debug offers:
Streamlined debugging process: Easily debug local and remote containerized applications, even those not running, directly from Docker Desktop.
Cross-device and cloud compatibility: Initiate debugging effortlessly from any device, whether local or in the cloud, enhancing flexibility and productivity.
Docker Debug improves productivity and seamless integration. The docker debug command simplifies attaching a shell to any container or image. This capability reduces the cognitive load on developers, allowing them to focus on solving problems rather than configuring their environment.
Ensuring reliable image builds with Docker Build checks
Docker Desktop 4.33 was a big release because, in addition to including the GA release of Docker Debug, it included the GA release of Docker Build checks, a new feature that ensures smoother and more reliable image builds. Build checks automatically validate common issues in your Dockerfiles before the build process begins, catching errors like invalid syntax, unsupported instructions, or missing dependencies. By surfacing these issues upfront, Docker Build checks help developers save time and avoid costly build failures.
You can access Docker Build checks in the CLI and in the Docker Desktop Builds view. The feature also works seamlessly with Docker Build Cloud, both locally and through CI. Whether you’re optimizing your Dockerfiles or troubleshooting build errors, Docker Build checks let you create efficient, high-quality container images with confidence — streamlining your development workflow from start to finish.
Onboarding and learning resources for developer success
To further reduce friction, Docker revamped its learning resources and integrated new tools to enhance developer onboarding. By adding beginner-friendly tutorials, Docker’s learning center makes it easier for developers to ramp up and quickly learn to use Docker tools, helping them spend more time coding and less time troubleshooting.
As Docker continues to rank as a top developer tool globally, we’re dedicated to empowering our community with continuous learning support.
Built-in container security from code to production
In an era where software supply chain security is essential, Docker has raised the bar on container security. With integrated security measures across every phase of the development lifecycle, Docker helps teams build, test, and deploy confidently.
Proactive security insights with Docker Scout Health Scores
Docker Scout, launched in 2023, has become a cornerstone of Docker’s security ecosystem, empowering developer teams to identify and address vulnerabilities in container images early in the development lifecycle. By integrating with Docker Hub, Docker Desktop, and CI/CD workflows, Scout ensures that security is seamlessly embedded into every build.
Addressing vulnerabilities during the inner loop — the development phase — is estimated to be up to 100 times less costly than fixing them in production. This underscores the critical importance of early risk visibility and remediation for engineering teams striving to deliver secure, production-ready software efficiently.
In 2024, we announced Docker Scout Health Scores (Figure 3), a feature designed to better communicate the security posture of container images development teams use every day. Docker Scout Health Scores provide a clear, alphabetical grading system (A to F) that evaluates common vulnerabilities and exposures (CVEs) for software components within Docker Hub. This feature allows developers to quickly assess and wisely choose trusted content for a secure software supply chain.
Air-gapped containers: Enhanced security for isolated environments
Docker introduced support for air-gapped containers in Docker Desktop 4.31, addressing the unique needs of highly secure, offline environments. Air-gapped containers enable developers to build, run, and test containerized applications without requiring an active internet connection.
This feature is crucial for organizations operating in industries with stringent compliance and security requirements, such as government, healthcare, and finance. By allowing developers to securely transfer container images and dependencies to air-gapped systems, Docker simplifies workflows and ensures that even isolated environments benefit from the power of containerization.
Strengthening trust with SOC 2 Type 2 and ISO 27001 certifications
Docker also achieved two major milestones in its commitment to security and reliability: SOC 2 Type 2 attestation and ISO 27001 certification. These globally recognized standards validate Docker’s dedication to safeguarding customer data, maintaining robust operational controls, and adhering to stringent security practices. SOC 2 Type 2 attestation focuses on the effective implementation of security, availability, and confidentiality controls, while ISO 27001 certification ensures compliance with best practices for managing information security systems.
These certifications provide developers and organizations with increased confidence in Docker’s ability to support secure software supply chains and protect sensitive information. They also demonstrate Docker’s focus on aligning its services with the needs of modern enterprises.
Accelerating success for development teams and organizations
In 2024, Docker introduced a range of features and enhancements designed to empower development teams and streamline operations across organizations. From harnessing the potential of AI to simplifying deployment workflows and improving security, Docker’s advancements are focused on enabling teams to work smarter and build with confidence. By addressing key challenges in development, management, and security, Docker continues to drive meaningful outcomes for developers and businesses alike.
Docker Home: A central hub to access and manage Docker products
Docker introduced Docker Home (Figure 4), a central hub for users to access Docker products, manage subscriptions, adjust settings, and find resources — all in one place. This approach simplifies navigation for developers and admins. Docker Home allows admins to manage organizations, users, and onboarding processes, with access to dashboards for monitoring Docker usage.
Future updates will add personalized features for different roles, and business subscribers will gain access to tools like the Docker Support portal and organization-wide notifications.
Figure 4: Docker Home.
Empowering AI innovation
Docker’s ecosystem supports AI/ML workflows, helping developers work with these cutting-edge technologies while staying cloud-native and agile. Read the Docker Labs GenAI series to see how we’re innovating and experimenting in the open.
Through partnerships like those with NVIDIA and GitHub, Docker ensures seamless integration of AI tools, allowing teams to rapidly experiment, deploy, and iterate. This emphasis on enabling advanced tech aligns Docker with organizations looking to leverage AI and ML in containerized environments.
Optimizing AI application development with Docker Desktop and NVIDIA AI Workbench
Docker and NVIDIA partnered to integrate Docker Desktop with NVIDIA AI Workbench, streamlining AI development workflows. This collaboration simplifies setup by automatically installing Docker Desktop when selected as the container runtime in AI Workbench, allowing developers to focus on creating, testing, and deploying AI models without configuration hassles. By combining Docker’s containerization capabilities with NVIDIA’s advanced AI tools, this integration provides a seamless platform for model training and deployment, enhancing productivity and accelerating innovation in AI application development.
We announced that Docker joined GitHub’s Partner Program and unveiled the Docker extension for GitHub Copilot (@docker). This extension is designed to assist developers in working with Docker directly within their GitHub workflows. This integration extends GitHub Copilot’s technology, enabling developers to generate Docker assets, learn about containerization, and analyze project vulnerabilities using Docker Scout, all from within the GitHub environment.
Accelerating AI development with the Docker AI catalog
Docker launched the AI Catalog, a curated collection of generative AI images and tools designed to simplify and accelerate AI application development. This catalog offers developers access to powerful models like IBM Granite, Llama, Mistral, Phi 2, and SolarLLM, as well as applications such as JupyterHub and H2O.ai. By providing essential tools for machine learning, model deployment, inference optimization, orchestration, ML frameworks, and databases, the AI Catalog enables developers to build and deploy AI solutions more efficiently.
The Docker AI Catalog addresses common challenges in AI development, such as decision overload from the vast array of tools and frameworks, steep learning curves, and complex configurations. By offering a curated list of trusted content and container images, Docker simplifies the decision-making process, allowing developers to focus on innovation rather than setup. This initiative underscores Docker’s commitment to empowering developers and publishers in the AI space, fostering a more streamlined and productive development environment.
Streamlining enterprise administration
Simplified deployment and management with Docker’s MSI and PKG installers
Docker simplifies deploying and managing Docker Desktop with the new MSI Installer for Windows and PKG Installer for macOS. The MSI Installer enables silent installations, automated updates, and login enforcement, streamlining workflows for IT admins. Similarly, the PKG Installer offers macOS users easy deployment and management with standard tools. These installers enhance efficiency, making it easier for organizations to equip teams and maintain secure, compliant environments.
These new installers also align with Docker’s commitment to simplifying the developer experience and improving organizational management. Whether you’re setting up a few machines or deploying Docker Desktop across an entire enterprise, these tools provide a reliable and efficient way to keep teams equipped and ready to build.
New sign-in enforcement options enhance security and help streamline IT administration
Docker simplifies IT administration and strengthens organizational security with new sign-in enforcement options for Docker Desktop. These features allow organizations to ensure users are signed in while using Docker, aligning local software with modern security standards. With flexible deployment options — including macOS Config Profiles, Windows Registry Keys, and the cross-platform registry.json file — IT administrators can easily enforce policies that prevent tampering and enhance security. These tools empower organizations to manage development environments more effectively, providing a secure foundation for teams to build confidently.
Desktop Insights: Unlocking performance and usage analytics
Docker introduced Desktop Insights, a powerful feature that provides developers and teams with actionable analytics to optimize their use of Docker Desktop. Accessible through the Docker Dashboard, Desktop Insights offers a detailed view of resource usage, build times, and performance metrics, helping users identify inefficiencies and fine-tune their workflows (Figure 5).
Whether you’re tracking the speed of container builds or understanding how resources like CPU and memory are being utilized, Desktop Insights empowers developers to make data-driven decisions. By bringing transparency to local development environments, this feature aligns with Docker’s mission to streamline container workflows and ensure developers have the tools to build faster and more effectively.
Figure 5: Desktop Insights dashboard.
New usage dashboards in Docker Hub
Docker introduced Usage dashboards in Docker Hub, giving organizations greater visibility into how they consume resources. These dashboards provide detailed insights into storage and image pull activity, helping teams understand their usage patterns at a granular level (Figure 6).
By breaking down data by repository, tag, and even IP address, the dashboards make it easy to identify high-traffic images or repositories that might require optimization. With this added transparency, teams can better manage their storage, avoid unnecessary pull requests, and optimize workflows to control costs.
Usage dashboards enhance accountability and empower organizations to fine-tune their Docker Hub usage, ensuring resources are used efficiently and effectively across all projects.
Figure 6: Usage dashboard.
Enhancing security with organization access tokens
Docker introduced organization access tokens, which let teams manage access to Docker Hub repositories at an organizational level. Unlike personal access tokens tied to individual users, these tokens are associated with the organization itself, allowing for centralized control and reducing reliance on individual accounts. This approach enhances security by enabling fine-grained permissions and simplifying the management of automated processes and CI/CD pipelines.
Organization access tokens offer several advantages, including the ability to set specific access permissions for each token, such as read or write access to selected repositories. They also support expiration dates, aligning with compliance requirements and bolstering security. By providing visibility into token usage and centralizing management within the Admin Console, these tokens streamline operations and improve governance for organizations of all sizes.
Docker’s vision for 2025
Docker’s journey doesn’t end here. In 2025, Docker remains committed to expanding its support for cloud-native and AI/ML development, reinforcing its position as the go-to container platform. New integrations and expanded multi-cloud capabilities are on the horizon, promising a more connected and versatile Docker ecosystem.
As Docker continues to build for the future, we’re committed to empowering developers, supporting the open source community, and driving efficiency in software development at scale.
2024 was a year of transformation for Docker and the developer community. With major advances in our product suite, continued focus on security, and streamlined experiences that deliver value, Docker is ready to help developer teams and organizations succeed in an evolving tech landscape. As we head into 2025, we invite you to explore Docker’s suite of tools and see how Docker can help your team build, innovate, and secure software faster than ever.
This ongoing Docker Labs GenAI series explores the exciting space of AI developer tools. At Docker, we believe there is a vast scope to explore, openly and without the hype. We will share our explorations and collaborate with the developer community in real time. Although developers have adopted autocomplete tooling like GitHub Copilot and use chat, there is significant potential for AI tools to assist with more specific tasks and interfaces throughout the entire software lifecycle. Therefore, our exploration will be broad. We will be releasing software as open source so you can play, explore, and hack with us, too.
In our past experiments, we started our work from the assumption that we had a project ready to work on. That means someone like a UI tech writer would need to understand Git operations in order to use the tools we built for them. Naturally, because we have been touching on Git so frequently, we wanted to try getting a Git agent started. Then, we want to use this Git agent to understand PR branches for a variety of user personas — without anyone needing to know the ins and outs of Git.
Git as an agent
We are exploring the idea that tools are agents. So, what would a Git agent do?
Let’s tackle our UI use case prompt.
Previously:
You are at $PWD of /project, which is a git repo.
Force checkout {{branch}}
Run a three-dot diff of the files changed in {{branch}} compared to main using --name-only.
A drawback that isn’t shown here, is that there is no authentication. So, if you haven’t fetched that branch or pulled commits already, this prompt at best will be unreliable and more than likely will fail (Figure 1):
Figure 1: No authentication occurs.
Now:
You are a helpful assistant that checks a PR for user-facing changes.
1. Fetch everything and get on latest main.
2. Checkout the PR branch and pull latest.
3. Run a three-dot git diff against main for just files. Write the output to /thread/diff.txt.
This time around, you can see that we are being less explicit about the Git operations, we have the ability to export outputs to the conversation thread and, most importantly, we have authentication with a new prompt!
Preparing GitHub authentication
Note: These prompts should be easily adaptable to other Git providers, but we use GitHub at Docker.
Before we can do anything with GitHub, we have to authenticate. There are several ways to do this, but for this post we’ll focus on SSH-based auth rather than using HTTPS through the CLI. Without getting too deep into the Git world, we will be authenticating with keys on our machine that are associated with our account. These keys and configurations are commonly located at ~/.ssh on Linux/Mac. Furthermore, users commonly maintain Git config at ~/.gitconfig.
The .gitconfig file is particularly useful because it lets us specify carriage return rules — something that can easily cause Git to fail when running in a Linux container. We will also need to modify our SSH config to remove UseKeychain. We found these changes are enough to authenticate using SSH in Alpine/Git. But we, of course, don’t want to modify any host configuration.
We came up with a fairly simple flow that lets us prepare to use Git in a container without messing with any host SSH configs.
Readonly mounts: Git config and SSH keys are stored on specific folders on the host machine. We need to mount those in. a. Mount ~/.ssh into a container as /root/.ssh-base readonly. b. Mount ~/.gitconfig into the same container as /root/.gitconfig.
Copy /root/.ssh-base to /root/.ssh and make the new file readwrite.
Make necessary changes to config.
For the LLM, we also need it to verify the config is in the thread and the changes were made to it. In the event that it fails to make the right changes, the LLM can self-correct.
Copy the .ssh directory and .gitconfig to /thread.
All of this is baked in a prompt you can find and run on GitHub. Simply replace <username> with your system username (Figure 2).
Figure 2: Readonly mounts.
If you’re using the default behavior in our extension for VSCode, then the /thread/ volume is ephemeral, so you would need to make sure your agent runs it before any Git tools. However, if you use the Set prompt thread ID command in VSCode, you can keep the /thread volume around under your own tag (Figure 3).
Tagging the thread persists everything after the prompt completes, so you would only need to run the prompt once before going on to develop your Git tools.
Figure 3: Set the prompt thread ID.
If you opt to persist the thread, then this prompt would only need to be run once and the Git credentials will stick around (Figure 4).
Figure 4: Stored credential data.
Now that we have our credentials ready, we need our Git tool to pick up on them.
Our container definition copies the SSH credentials and .gitconfig files to the correct directory before running Git commands.
Unpacking objects: 90% (9/10)
Unpacking objects: 100% (10/10)
Unpacking objects: 100% (10/10), 4.14 KiB | 141.00 KiB/s, done.
From github.com:docker/repo
abcd123..abcd123 main -> origin/main
* [new tag] branch/v2982.0.0 -> branch/v2982.0.0
# ROLE assistant
I have fetched all origin branches. The latest updates have been applied to your local repository, and any new tags have been downloaded.
```
Now, we can see our Git tool is authenticated as if it were us.
Running the agent now, it can:
## ROLE assistant
I have run the git fetch --all command, which retrieves updates from all remotes. If you need further assistance with your Git repository, feel free to ask!
```
# ROLE assistant
```json
{"request":"checkout main"}
```
## ROLE assistant
```json
{"args":"checkout main"}
```
## ROLE assistant
You are already on the 'main' branch, and it is up to date with 'origin/main'.
```
# ROLE assistant
```json
{"request":"checkout the branch branch and pull latest changes."}
```
...
## ROLE assistant
The branch branch has been successfully checked out, and it's already up to date with the latest changes.
...
# ROLE assistant
```json
{"request":"Run a three-dot git diff against main and write the output for just files to /thread/diff.txt."}
```
...
## ROLE assistant
```json
{"args":"diff main... --name-only","outfile":"/thread/diff.txt"}
```
*entering tool*
## ROLE tool (git)
file1.tsx
file2.tsx
...
## ROLE assistant
The three-dot Git diff against the main branch has been executed, and the output has been saved to /thread/diff.txt. This includes the names of files that have differences.
``
With the new Git agent, we have enabled our assistant to fetch new information from upstream, switch branches, and pull in new code to review. If we provide our agent with credentials that are limited to read-only access, this agent could be used by someone that does not have a local git install.
For more on what we’re doing at Docker, subscribe to our newsletter.
This ongoing Docker Labs GenAI series explores the exciting space of AI developer tools. At Docker, we believe there is a vast scope to explore, openly and without the hype. We will share our explorations and collaborate with the developer community in real time. Although developers have adopted autocomplete tooling like GitHub Copilot and use chat, there is significant potential for AI tools to assist with more specific tasks and interfaces throughout the entire software lifecycle. Therefore, our exploration will be broad. We will be releasing software as open source so you can play, explore, and hack with us, too.
Can an AI-powered assistant understand a GitHub repo enough to answer questions for UI writers?
Across many projects, user-facing content is rendered based on some sort of client-side code. Whether a website, a game, or a mobile app, it’s critical to nail the text copy displayed to the user.
So let’s take a sample question: Do any open PRs in this project need to be reviewed for UI copy? In other words, we want to scan a GitHub repo’s PRs and gain intelligence about the changes included.
Disclaimer: The best practice to accomplish this at a mature organization would be to implement Localization (i18n), which would facilitate centralized user-facing text. However, in a world of AI-powered tools, we believe our assistants will help minimize friction for all projects, not just ones that have adopted i18n.
So, let’s start off by seeing what options we already have.
The first instinct someone might have is to open the new copilot friend in the GitHub nav
Figure 1: Type / to search.
We tried to get it to answer basic questions, first: “How many PR’s are open?”
Figure 2: How many PR’s are there open? The answer doesn’t give a number.
Despite having access to the GitHub repo, the Copilot agent provides less helpful information than we might expect.
Figure 3: Copilot is powered by AI, so mistakes are possible.
We don’t even get a number like we asked, despite GitHub surfacing that information on the repository’s main page. Following up our first query with the main query we want to ask effectively just gives us the same answer
Figure 4: The third PR is filesharing: add some missing contexts.
And, after inspecting the third PR in the list, it doesn’t contain user-facing changes. One great indicator for this web project is the lack of any clientside code being modified. This was a backend change so we didn’t want to see this one.
Figure 5: The PR doesn’t contain user-facing changes.
So let’s try to improve this:
First prompt file
---
functions:
- name: bash
description: Run a bash script in the utilities container.
parameters:
type: object
properties:
command:
type: string
description: The command to send to bash
container:
image: wbitt/network-multitool
command:
- "bash"
- "-c"
- "{{command|safe}}"
- name: git
description: Run a git command.
parameters:
type: object
properties:
command:
type: string
description: The git command to run, excluding the `git` command itself
container:
image: alpine/git
entrypoint:
- "/bin/sh"
command:
- "-c"
- "git --no-pager {{command|safe}}"
---
# prompt system
You are a helpful assistant that helps the user to check if a PR contains any user-facing changes.
You are given a container to run bash in with the following tools:
curl, wget, jq
and default alpine linux tools too.
# prompt user
You are at $PWD of /project, which is a git repo.
Checkout branch `{{branch}}`.
Diff the changes and report any containing user facing changes
This prompt was promising, but it ended up with a few blocking flaws. The reason is that using git to compare files is quite tricky for an LLM.
git diff uses a pager, and therefore needs the --no-pager arg to send stdout to the conversation.
The total number of files affected via git diff can be quite large.
Given each file, the raw diff output can be massive and difficult to parse.
The important files changed in a PR might be buried with many extra files in the diff output.
The container has many more tools than necessary, allowing the LLM to hallucinate.
The agent needs some understanding of the repo to determine the sorts of files that contain user-facing changes, and it needs to be capable of seeing just the important pieces of information.
Our next pass involves a few tweaks:
Switch to alpine git image and a file writer as the only tools necessary.
Use –files-only and –no-pager args.
# ROLE assistant
The following files are likely to contain user-facing changes as they mainly consist of UI components, hooks, and API functionalities.
```
file1.ts
fil2.tsx
file3.tsx
...
```
Remember that this isn't a guarantee of whether there are user-facing changes, but just an indication of where they might be if there are any.
Remember that this isn’t a guarantee of whether there are user-facing changes, but just an indication of where they might be if there are any.
Giving the agent the tool run-javascript-sandbox allowed our agent to write a script to save the output for later.
Figure 6: Folder called user-changes with files.txt.
This is a great start; however, we now need to inspect the files themselves for user-facing changes. When we started this, we realized that user-facing changes could manifest in a diverse set of “diff”s so we needed to include expert knowledge. We synced up with Mark Higson, a staff SWE currently working on the frontend platform here at Docker. Mark was able to help provide some key advice for what “user-facing” changes look like in many repos at Docker, so I baked the tips into the prompt.
Straightforward approaches
Looking for changes in text nodes found in a JSX tree is the easiest example.
JSX node with interpolation
<div>{functionReturningString()}</div>
If the result is a string, the result is probably user-facing, but the components that create the string could be elsewhere, so look for:
Nuanced indicators
Standard user-facing components. Example: notifications. If a notification’s props change, we can likely infer that it is a user-facing change.
Constructors for commonly used components. Example: errors. If an Error() is constructed with a different argument, we know that error could show up differently.
The key for UI reviewers is the overall amount of text is changed, rather than layout.
So, despite not being able to catch everything that could be rendered, we will be able to deliver value by focusing on these areas.
Diffing the files
There are a few approaches to finding changes in the files. To start, we’ll use git again.
Before including expert advice, git diff was hallucinating changes that weren’t actually represented in the output. After the expert advice, we are seeing much more focused outputs from the LLM.
Our second prompt just needs to read the user-facing files that we already saved, and then compare them to main. After a bit of trial and error with git, we found that a combination of --no-color and --minimal was able to give the LLM enough context without consuming too many tokens for each change.
There’s a lot of buzz around generating and reading diffs with LLMs. The teams at Aider and Cursor are both focusing on fine-tuning LLM’s using speculative decoding:
For our use cases, however, we found that the average “big” PR at Docker was not a problem for traditional LLMs when given good advice and the right tools.
So here’s the second prompt:
## User-facing content
The following pieces of code are what we want to focus on for user-facing content:
Text Nodes in any JSX or TSX files.
Text Nodes in any HTML files.
Standard user-facing components. Example: Definitions/Constructors for notifications, toasts, and errors.
# prompt user
Can you tell me if there are any user-facing changes in {{branch}}?
Note: Some full paths, branches, and diffs are trimmed or replaced with placeholders for this article.
# ROLE assistant
```json
{
"args": ["checkout", "branch"]
}
```
# ROLE tool (git)
Already on 'branch'
Your branch is up to date with 'origin/branch'.
# ROLE assistant
```json
{
"path": "/thread/user-changes/files.txt"
}
```
*entering tool*
# ROLE tool (read-file)
path1
path2
path3
...rest of paths
# ROLE assistant
```json
{
"args": ["diff", "main", "--no-color", "--minimal", path1 path2 path3...]
}
```
*entering tool*
# ROLE tool (git)
<Diff output truncated>
# ROLE assistant
The following user-facing changes were detected between the "main" branch and the "branch" branch:
1. In `File1.tsx` file, the text "Sign In" was modified to "Sign in".
2. In `File2.ts` file, titles "Databases & Storage", "Monitoring & Observability", "Developer Tools", "New Extensions", were changed to "Databases & storage", "Monitoring & observability", "Developer tools", "New extensions" respectively.
3. In `File3.rtl.test.tsx.snap` and `ImageHeader/index.tsx files`, the text "Compressed Size " was changed to "Compressed size".
4. In `File4.rtl.test.tsx` and `ImageDetail/index.tsx files`, a test-case previously checking for the existence of "Compressed Size" now looks for "Compressed size".
5. In `File5.tsx file`, the button text "Add Collaborator" has been changed to "Add collaborator".
6. In `route.tsx file`, the collaborators table title "Current Collaborators" was changed to "Current collaborators".
7. In `File6.tsx` file, the description was updated.
8. In `File7.tsx`, `RepositoryOverview.tsx`, `RepositoryReadMe.tsx`, `TagsAndScans.tsx` files, the description when there is no category or description was updated.
9. In `File8.rtl.test.tsx`, `DeleteRepo.tsx`, the text for confirming repo deletion and the delete button text was adjusted.
10. In `route.tsx file`, the filter label "Trusted Content" was changed to "Trusted content".
11. In `File9.tsx`, the text "Your Organizations" has been changed to "Your organizations".
12. In `Component/index.tsx`, the search group label "Trusted Content" has been changed to "Trusted content".
13. In `file10.test.ts` file, a test-case was updated to check for the new text "Sign in".
```
The changes in the `branch` branch compared to `main` include several modifications that affect user-facing content, particularly in JSX and TSX files. Here is a summary of the key changes:
...
These changes primarily involve simplification and refactoring of the existing UI logic, possibly to streamline the user interaction by removing complexities related to feature flags and reducing the use of modals or conditional rendering for specific purchasing flows.
This is already a promising flow. For example, a tech writer could clone the git repo and run this prompt to inspect a branch for user-facing changes. From here, we might extend the functionality:
Allow user input for PR to review without knowing the branch or git needing to use git.
Automatic git clone & pull with auth.
Support for larger >15 files changed PR by allowing agents to automate their tasks.
“Baking” the final flow into CI/CD so that it can automatically assign reviewers to relevant PRs.
If you’re interested in running this prompt on your own repo or just want to follow along with the code, watch our new public repo and reach out. We also appreciate your GitHub Stars.
Everything we’ve discussed in this blog post is available for you to try out on your own projects.
For more on what we’re doing at Docker, subscribe to our newsletter.





















 Cool Projects from the Community to get inspiration and tutorials
Cool Projects from the Community to get inspiration and tutorials Product Updates: firmware update, new product spoiler
Product Updates: firmware update, new product spoiler Wiki Updates: new wikis + wiki contribution
Wiki Updates: new wikis + wiki contribution News: events, contests, and other community stuff
News: events, contests, and other community stuff to subscribe now!
to subscribe now!